In 2023, AI stopped being a topic limited to research labs, innovation teams, or technical communities. It became part of executive discussion, product strategy, and enterprise planning at a global scale. The release and rapid adoption of generative AI systems created an entirely new level of urgency. Suddenly, companies that had previously explored AI cautiously were now asking whether they were moving too slowly. Teams that had never considered advanced machine learning began testing AI assistants, workflow automation, content generation, customer support tools, and domain-specific reasoning systems. It felt as though a new software era had arrived all at once.
But as the first wave of excitement settled into actual experimentation, organizations ran into a more practical question. If AI was going to become an operational capability rather than just a fascinating demo, what data would it actually learn from? This question exposed a problem that had existed for years but had never been felt at such scale. The most valuable AI systems required more than strong models. They required access to high-quality, relevant, safe, and sufficiently diverse training and evaluation data. That realization is one of the main reasons synthetic data emerged as a critical AI topic in 2023.
Before 2023, synthetic data had already existed in important corners of the AI world. It had value in simulation-heavy domains, robotics, autonomous systems, privacy-sensitive analytics, and computer vision workflows where rare scenarios or expensive labeling made real-world collection difficult. But these discussions had often remained somewhat specialized. In 2023, the context changed. Generative AI dramatically expanded the number of organizations that suddenly wanted to build intelligent systems. That growth exposed a structural mismatch between ambition and data readiness. Many teams wanted enterprise-grade AI performance, but the real-world data available to them was incomplete, fragmented, sensitive, or simply not aligned with the use case.
One reason this shift became so visible is that generative AI changed how people thought about software capability. A powerful model made it easier to imagine all kinds of applications: internal copilots, intelligent search, automation systems, AI-driven design, decision support tools, and domain-specific assistants. Yet as soon as these ideas were tested seriously, organizations discovered that real-world performance depended heavily on task-specific conditions. Broad capability at the model level did not guarantee useful behavior inside a business context. The system needed data that reflected the environment in which it would actually operate. That meant the market was no longer asking only for "more data." It was asking for more relevant data.
Synthetic data became increasingly attractive in that setting because it offered something traditional collection strategies often could not: intentionality. Instead of relying entirely on whatever examples happened to exist in the historical record, teams could begin defining what kinds of examples they needed and why. They could think in terms of missing scenarios, underrepresented events, privacy-sensitive structures, and domain-specific variations. This was a meaningful mental shift. Data was no longer treated only as a passive resource to be harvested. It started to be understood as something that could be strategically designed.
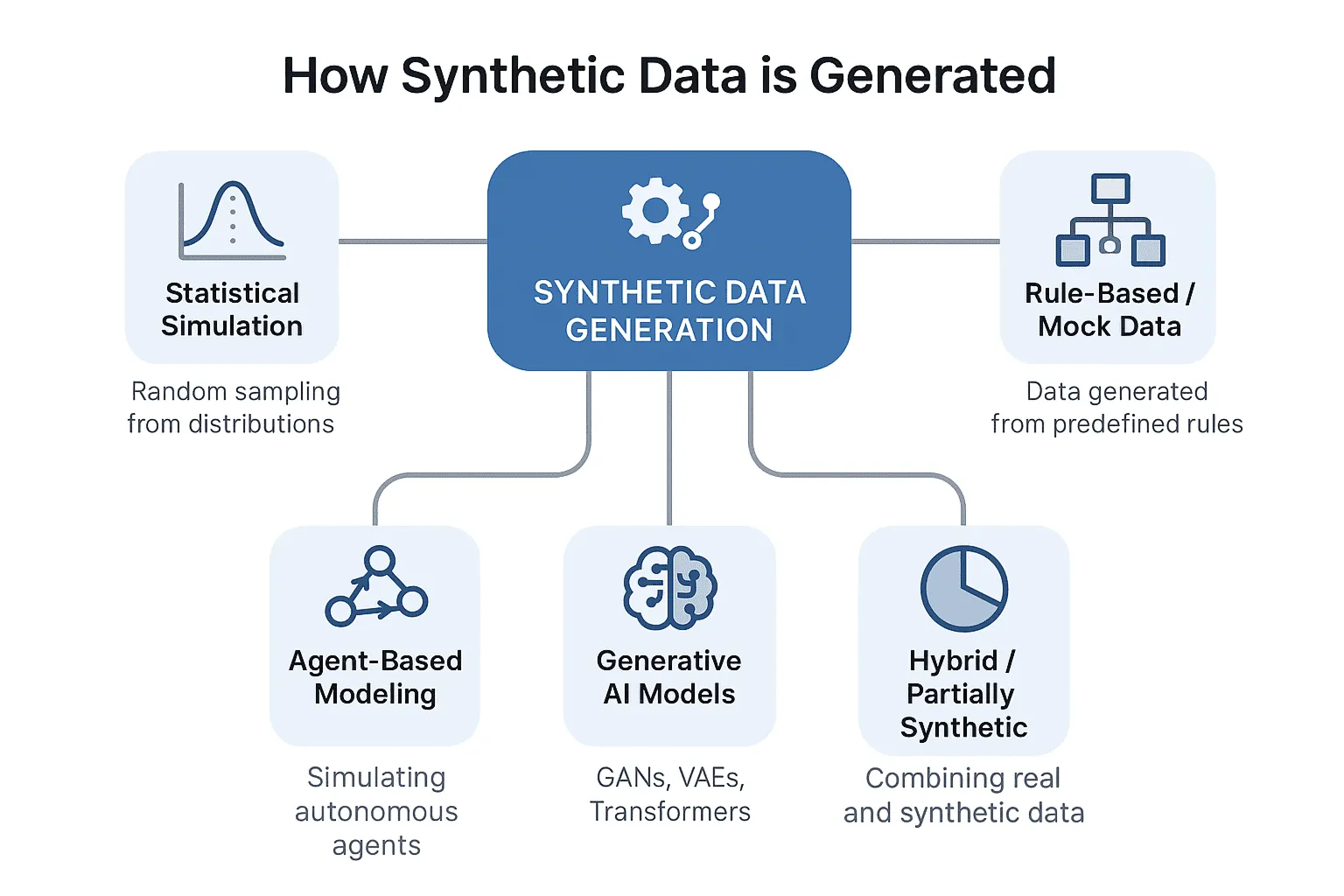
This design-oriented view became particularly important because real-world data creates several recurring bottlenecks at once. Some datasets are difficult to access because they contain personal or confidential information. Some are difficult to scale because annotation is expensive and slow. Some are sparse because the most important situations are rare by nature. Others are available in large quantity but misaligned with the problem the company is actually trying to solve. Synthetic data became a central topic in 2023 because it appeared to offer a path through these structural limits. It was not valuable simply because it was artificial. It was valuable because it allowed organizations to build around reality where reality alone was insufficient.
The long-tail problem was one of the biggest reasons this was true. Real systems often fail not on ordinary cases, but on rare and difficult ones. A defect detector may work on common product states and still fail on unusual damage patterns. A document assistant may handle standard requests but struggle with edge-case policy ambiguity. A perception model may perform well in clean environments and break down under glare, weather, clutter, or unusual object placement. In many of these situations, the real world does not produce enough examples quickly enough to support robust learning. Synthetic data became important because it offered a way to create these scenarios deliberately rather than waiting for them to emerge.
This was especially relevant for AI teams working in enterprise and industrial environments. A company trying to improve a manufacturing inspection pipeline, a healthcare analytics system, a robotics workflow, or a secure enterprise LLM often faced the same basic reality: the data that mattered most was either too rare, too sensitive, too expensive, or too operationally difficult to gather in the right form. In this context, synthetic data did not feel like an abstract idea from research papers. It began to feel like a practical response to a very immediate business constraint.
Another reason synthetic data gained so much relevance in 2023 is that the discussion around AI safety and governance also began to mature. Early market excitement was mostly about possibility. But once organizations started thinking about production use, they had to ask harder questions. Could they safely use real customer records? Could sensitive internal documents be brought into model development? Could they expose enterprise data to external systems without losing control? Could they test product behavior without creating legal or privacy risk? Synthetic data gained momentum partly because it offered an answer to these questions. It could create safer testing and prototyping environments where raw exposure to sensitive records was reduced.
This also changed the strategic value of simulation. Simulation was no longer seen only as an engineering tool or a robotics specialty. In 2023, it began to look like part of the broader AI data supply chain. If a company could simulate rare events, operational environments, spatial contexts, or edge-case workflows, it could generate more relevant training material than it would get from passive reliance on historical data alone. That made simulation and synthetic generation increasingly relevant even to teams that had not previously considered them central.
It is important, however, not to overstate what synthetic data solved in 2023. It did not replace the need for real data. It did not eliminate the challenges of realism, validation, or domain alignment. And it certainly did not make data quality concerns disappear. In fact, one of the key lessons emerging in 2023 was that synthetic data itself had to be engineered carefully. Poor synthetic generation could create misleading signals, unrealistic distributions, and false confidence. But that did not weaken the importance of the topic. It strengthened it. It meant that synthetic data was becoming a serious engineering discussion rather than a novelty.
Another subtle but important factor was competitive pressure. Once frontier models became more broadly accessible, companies needed to think more carefully about what would actually differentiate them. Many began to realize that competitive advantage would not come only from using a strong model, because many others would have access to the same or similar models. The advantage would increasingly come from proprietary data environments, scenario libraries, evaluation logic, and domain-specific preparation. Synthetic data became strategically important because it could become part of that defensible layer.
This is one reason why 2023 was such a meaningful turning point. The AI market did not simply discover synthetic data. It reinterpreted it. What had sometimes been treated as a secondary or niche method became more central because the broader AI economy had changed. The explosive popularity of generative systems created a new urgency around data scarcity, data governance, and task-specific readiness. Synthetic data became relevant not because it was fashionable, but because it aligned with the actual bottlenecks the market was beginning to feel.
Looking back, 2023 may be remembered as the year when the industry realized that AI scale without data strategy was not enough. Models created possibility. Synthetic data helped make that possibility more practical. It gave organizations a way to create what history had not provided, to test what reality had not yet revealed, and to move forward where privacy, scarcity, and cost were limiting progress.
That is why synthetic data emerged as a critical AI topic in 2023. It did not rise because enterprises suddenly wanted artificial data for its own sake. It rose because the next stage of AI required more intentional, more flexible, and more controllable ways of building the data environments that real-world intelligence depends on.