The synthetic data market has evolved rapidly. What was once treated as a highly specialized technical field is now increasingly recognized as part of the mainstream enterprise AI stack. In 2026, the category is entering a new phase of maturity. The market is no longer asking only whether synthetic data is useful. The more important question now is what will actually differentiate the companies building it.
This shift matters because category growth naturally reduces the value of generic positioning. As more providers appear and baseline capability improves, differentiation begins to move away from novelty and toward depth, fit, and credibility.
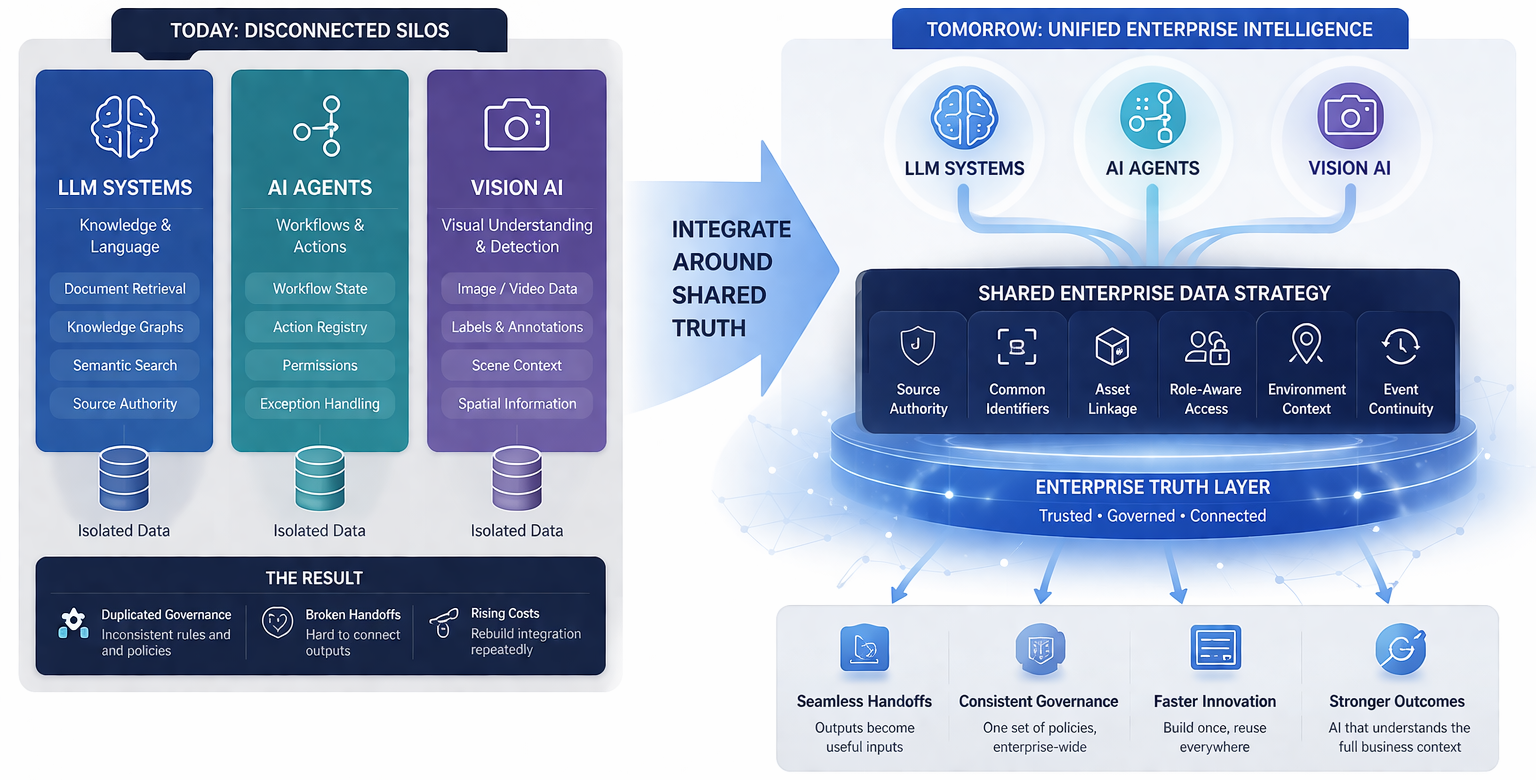
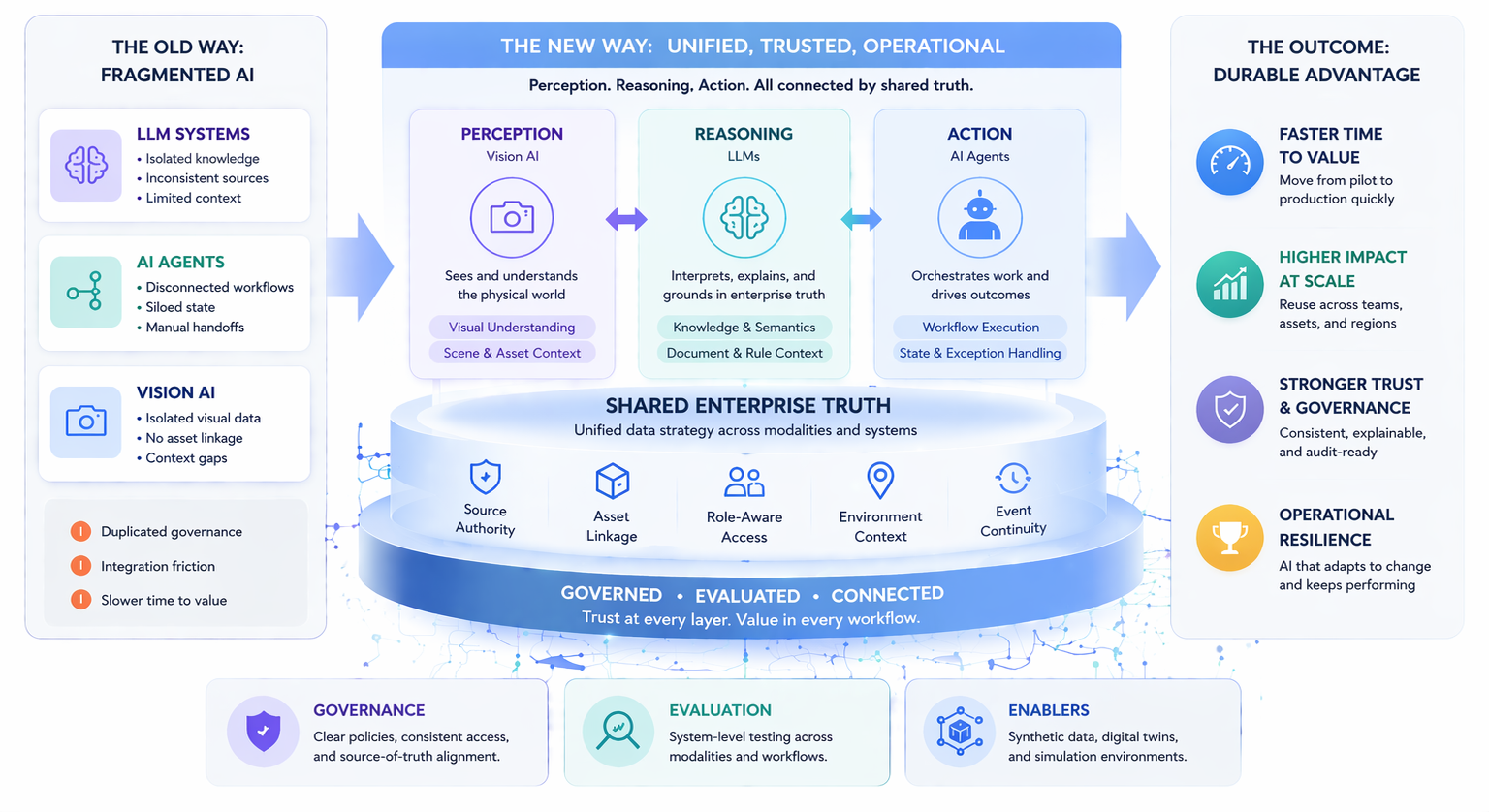
At a glance, this may seem like a subtle distinction. But in practice, it changes the entire conversation. Buyers want to understand whether the synthetic environment is reusable, whether it improves downstream outcomes, whether it is governed properly, whether it integrates into existing workflows, and whether it supports long-term operational value.
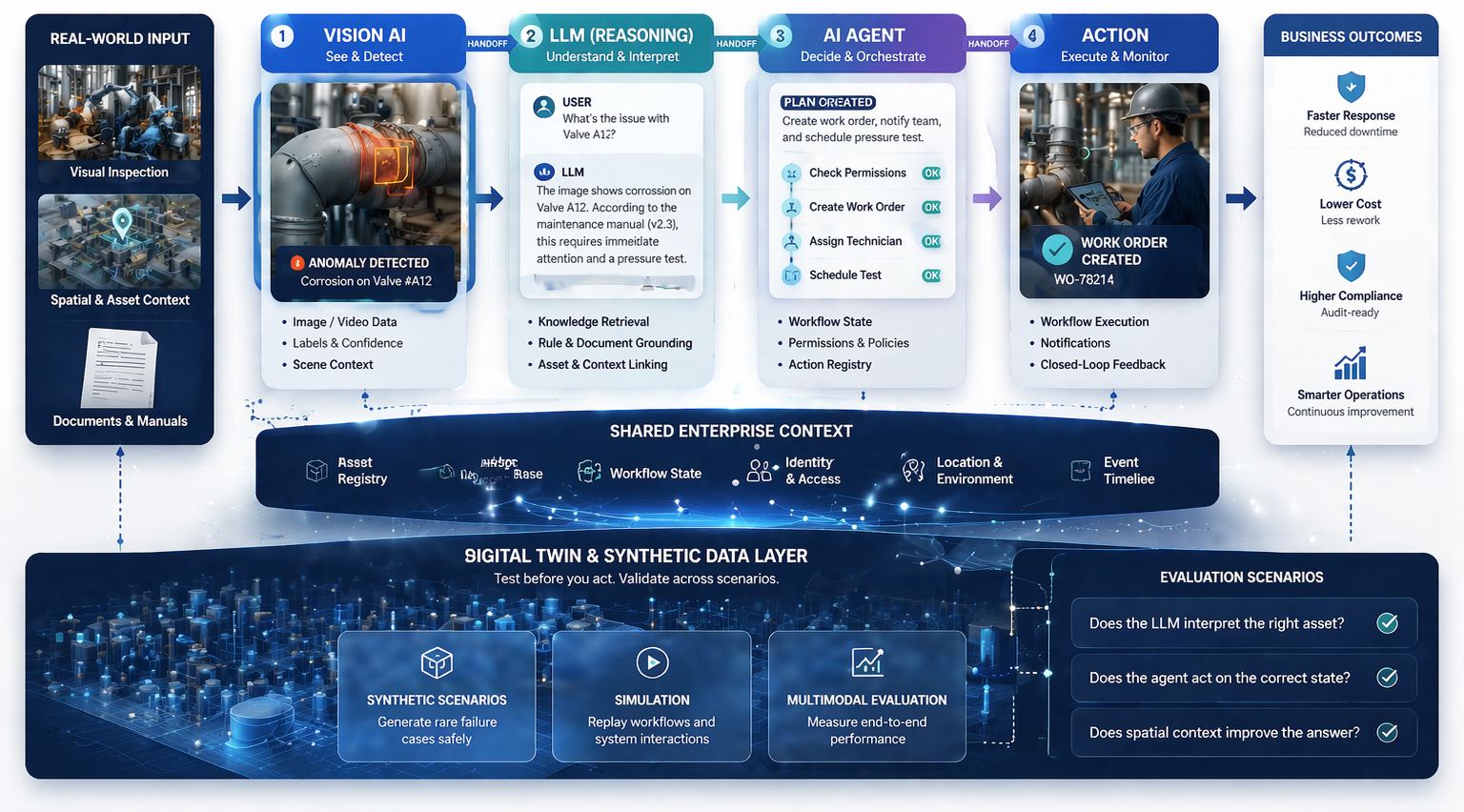
One of the clearest differentiators will be domain depth. Synthetic data is often discussed in broad, category-level language, but real enterprise value is always highly domain-specific. Companies that understand the detailed operating logic of one or more domains are much more likely to create trust at the enterprise level.