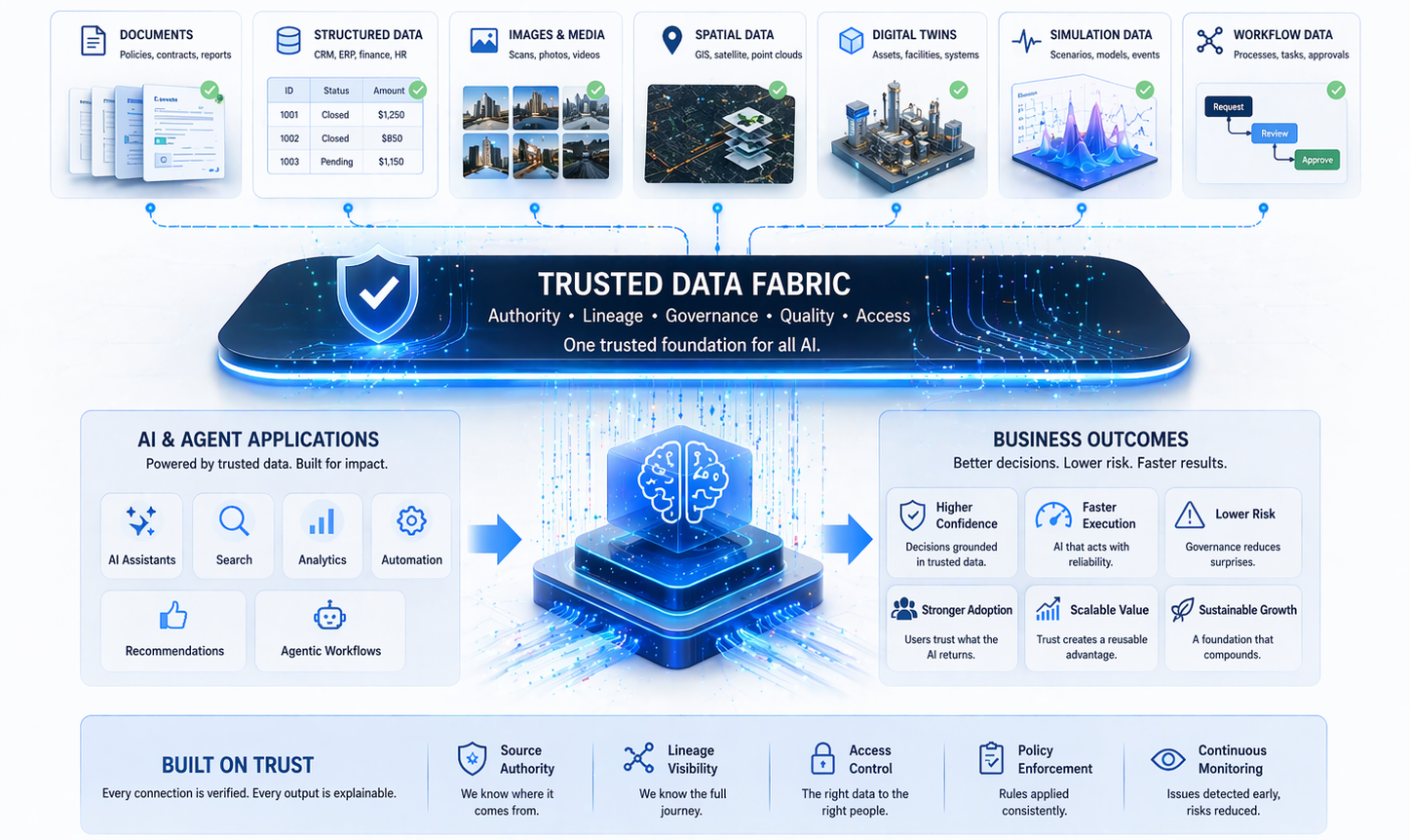
Most real-world datasets are built from ordinary life. Cameras record standard scenes. Sensors capture normal operations. Documents describe routine decisions. Customer interactions reflect common needs and recurring questions. This is both natural and useful. Day-to-day reality generates large volumes of data, and those volumes provide the statistical foundation for many successful AI systems. But there is a hidden weakness in this pattern: AI systems are typically trained on what happens most often, while they are judged most harshly on what happens least often.
Those rare situations are known as edge cases. They may involve unusual environmental conditions, unexpected object arrangements, safety incidents, abnormal user instructions, system anomalies, or rare combinations of factors that do not appear frequently in ordinary data collection. In a factory, an edge case might be a subtle defect that appears only under specific material or lighting conditions. In a drone system, it might be an unstable flight state during strong wind and partial sensor failure. In a robotics workflow, it might involve unexpected occlusion, collision risk, or off-normal human behavior. In an enterprise language system, it might be a prompt that combines policy ambiguity, urgency, and incomplete context. These events are statistically rare, but operationally they are often the moments that matter most.
This is why edge-case readiness is central to trustworthy AI. A system that performs well under normal conditions may still be fragile in reality if it has not been prepared for low-frequency, high-impact situations. In sectors involving safety, compliance, infrastructure, healthcare, finance, logistics, and automation, this fragility is not a minor technical issue. It becomes a business risk. A model that fails gracefully during common conditions but breaks during abnormal ones is not truly reliable.
The problem is that real-world collection is poorly suited to solving this issue at scale. Rare edge cases are difficult by definition. If a company waits for natural operations to produce enough examples, it may wait months or years. Even when rare events occur, they are not always captured cleanly. Sensors may miss the critical moment. Images may be low quality. Records may be incomplete. Labels may be inconsistent. In some environments, the rare event may be too dangerous, too costly, or too sensitive to reproduce deliberately. This creates a fundamental challenge: the scenarios most essential for robustness are often the scenarios least available for training.
Synthetic data provides a way through this bottleneck. Instead of treating rare events as inaccessible, it makes them designable. Organizations can create simulations of abnormal motion, unusual lighting, weather effects, occlusion, mechanical failures, structural defects, emergency situations, or edge-case user interactions. They can vary one parameter at a time, or combine multiple conditions to explore compounding difficulty. This transforms edge-case development from a passive waiting game into an active engineering process.
The value of this approach is especially visible in computer vision and physical AI systems. A vision model trained only on common cases may deliver impressive average accuracy, yet still fail under glare, fog, reflections, low light, clutter, unusual object orientation, material shifts, or surface damage. These are not hypothetical nuisances. They are exactly the kinds of conditions that emerge outside controlled demo environments. In many real deployments, the average case is not the real challenge. The long tail is.
Synthetic data allows teams to directly address the long tail. Instead of depending on random exposure to rare scenes, they can define the risk space in advance. They can ask: What types of abnormal events are costly? What failure modes are most likely to harm safety, trust, or operations? What visual conditions produce instability? What unusual sequences should a system be able to interpret? Once those questions are identified, synthetic generation can be used to build focused scenario libraries that expose the model to variations reality may never provide in sufficient quantity.
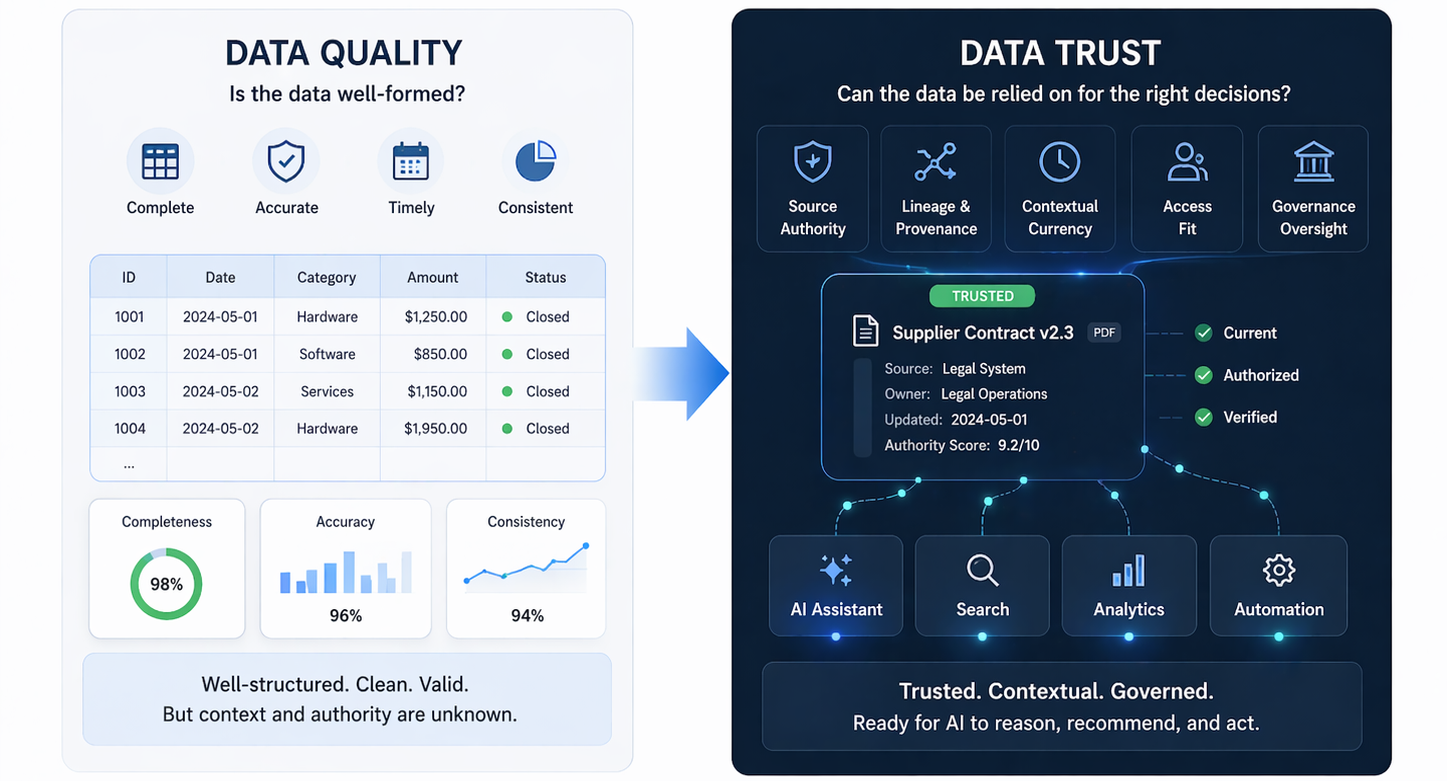
This is not only useful for training. It is equally important for evaluation. Many AI systems appear strong because they are tested on benchmark sets dominated by relatively standard examples. But production readiness depends on stress-testing under difficult conditions. Synthetic edge-case datasets make this possible. They allow organizations to build evaluation environments specifically designed to reveal brittleness, not merely confirm average competence. This is a much stronger way to measure whether a system is truly ready for deployment.
For example, an industrial inspection model may achieve high accuracy on commonly occurring product states while still missing rare defect geometries that are financially significant. A drone navigation system may function well in ordinary weather but become unstable during complex wind turbulence combined with partial visual occlusion. A warehouse vision system may correctly identify objects in standard layouts while failing when objects are deformed, stacked irregularly, or partially hidden. In each case, synthetic data enables teams to simulate meaningful stress conditions before failures happen in the field.
Another important advantage is repeatability. Real rare events are not only scarce; they are inconsistent. Even when they do happen, they do not occur under controlled experimental conditions. This makes it hard to isolate variables and understand exactly why a model failed. Synthetic simulation creates repeatable environments where conditions can be controlled. A team can modify lighting while keeping all else fixed, change camera angles without altering geometry, introduce surface anomalies incrementally, or simulate different severity levels of the same operational failure. This gives AI development teams a much more precise understanding of model behavior.
The strategic importance of this is significant. Organizations are increasingly expected not only to deploy AI, but to explain why it is reliable. This is especially relevant in regulated or safety-sensitive settings. It is no longer enough to say that a model performs well on average. Stakeholders want evidence that the system has been tested under difficult scenarios. Synthetic edge-case generation supports this kind of assurance by creating structured test regimes around risk-heavy situations. It helps turn robustness from a vague claim into something that can be demonstrated.
At the same time, the success of synthetic edge-case training depends on realism. Poorly designed synthetic scenarios can be misleading. If the generated cases exaggerate cues, simplify environment dynamics, or fail to represent the actual operational logic of the system, the resulting model may learn artificial patterns that do not transfer to the real world. This is one of the most important caveats in synthetic data design. The goal is not simply to make examples that look difficult. The goal is to recreate meaningful difficulty that reflects real deployment conditions.
That means synthetic edge-case generation works best when it is guided by domain knowledge. Engineers, operators, inspectors, safety teams, field specialists, and AI practitioners all have a role to play in defining what "rare but important" actually means. Edge cases are not just statistical outliers. They are operationally relevant outliers. A strong synthetic data pipeline therefore depends on understanding the environment deeply enough to know which rare conditions are worth simulating, which variables matter most, and which failure patterns are most costly.
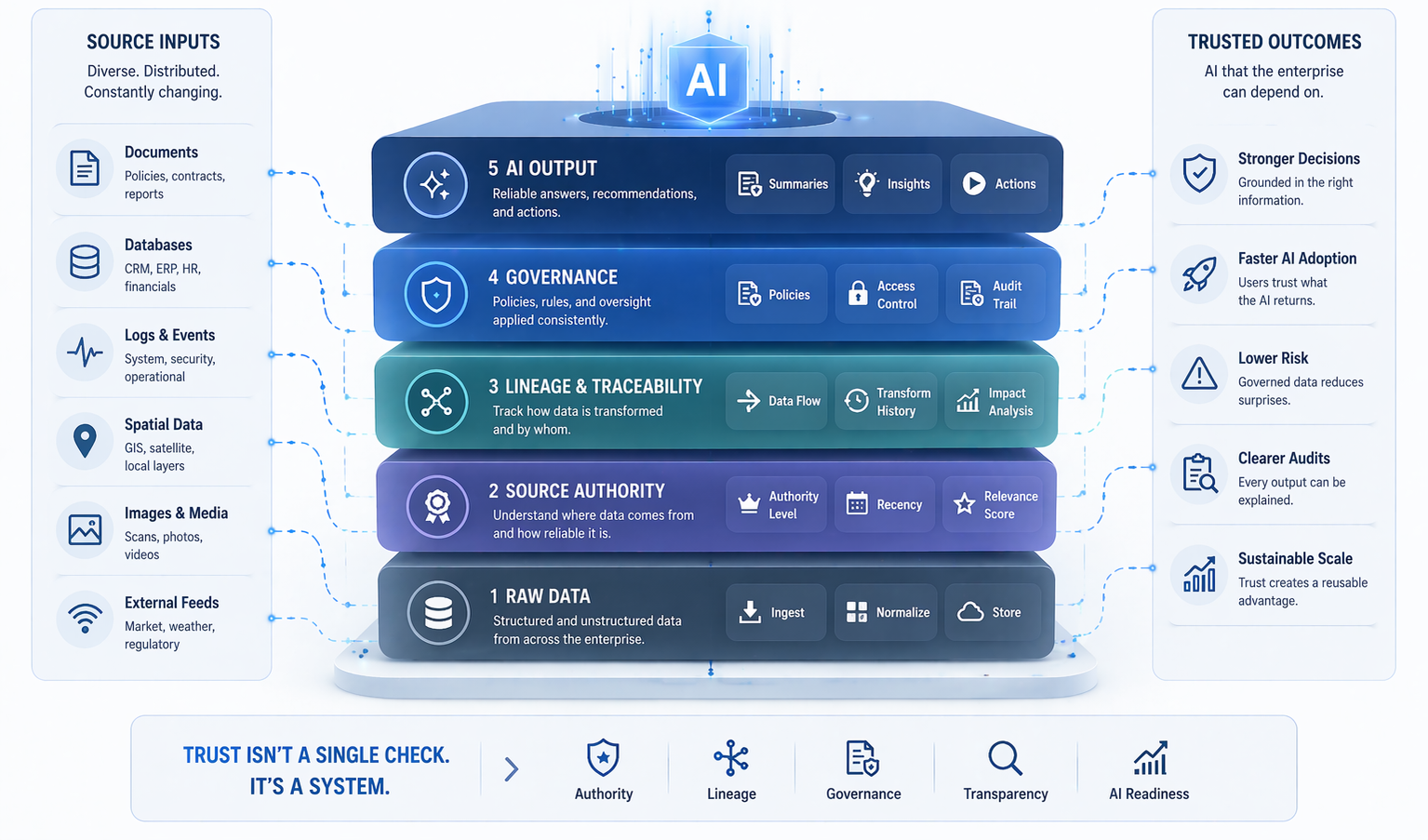
In many ways, synthetic edge-case data allows organizations to move from reactive learning to proactive resilience. Without it, teams often wait for real failures, collect examples after the damage, retrain the model, and repeat the cycle. This is expensive and slow. With synthetic simulation, they can anticipate likely problems earlier, create representative examples, evaluate robustness before deployment, and improve the model ahead of time. This does not eliminate the need for real-world feedback, but it significantly improves the starting point.
This is especially valuable in sectors where failure carries a high penalty. In manufacturing, a missed defect can create quality escapes, recall risk, and customer dissatisfaction. In robotics, a perception failure can trigger unsafe motion. In autonomous navigation, a rare scenario can become a catastrophic event. In enterprise AI, a rare edge instruction may trigger policy violations or reputational harm. In all of these cases, the rarity of the event does not reduce its importance. In fact, rarity often increases importance because it makes the system less prepared.
Synthetic data changes that preparedness equation. It allows rare conditions to become visible, trainable, and measurable. It gives organizations a way to build robustness where raw reality offers too little evidence. More importantly, it creates a mindset shift. Instead of asking whether enough edge-case data exists, teams can ask which critical conditions need to be represented and how those conditions should be simulated. That is a much more strategic approach to AI reliability.
As AI moves deeper into operational environments, success will depend less on average-case performance and more on failure resistance. The systems that matter most will not be the ones that merely perform well during predictable situations. They will be the ones that remain dependable when the environment changes, when inputs become messy, when objects appear in unfamiliar forms, and when users behave unexpectedly. Edge-case resilience is becoming a core criterion of production AI maturity.
That is the unique value of synthetic data for training rare edge cases. It does not simply generate more examples. It gives organizations access to the exact kinds of scenarios reality is least likely to provide at the scale they need, yet most likely to punish if ignored. In that sense, synthetic edge-case data is not just a technical convenience. It is one of the most practical tools available for building AI systems that can survive outside the lab.