Generative AI has changed the pace and direction of enterprise innovation. In a remarkably short period of time, companies moved from curiosity to experimentation, and from experimentation to real deployment discussions. In the early phase of this transformation, the spotlight was overwhelmingly on models. The market focused on parameter counts, benchmark scores, latency improvements, context windows, and multimodal capabilities. The assumption was simple: if the model became large enough and capable enough, value would naturally follow.
But as adoption matured, organizations began to run into a more difficult truth. Powerful models do not automatically create reliable, domain-ready, production-grade AI systems. In real business settings, the real constraint is often not compute, and not even the model itself. It is the quality, structure, relevance, and governance of the data behind the system. This is the context in which synthetic data is gaining renewed attention.
Synthetic data matters because it addresses a structural weakness in AI development: the data companies need most is often the data they cannot easily collect. Some data is too rare. Some is too expensive. Some is too sensitive. Some occurs only under risky or exceptional conditions. Some exists, but cannot legally or ethically be reused at scale. In many industries, the most valuable training and evaluation data sits behind exactly these barriers. Synthetic data provides a way to move forward without waiting for the real world to deliver perfect conditions on demand.
This renewed attention is not just a temporary trend. It reflects a deeper shift in how enterprises are thinking about AI. Instead of viewing data as a passive asset that must simply be gathered, more organizations are beginning to understand data as something that can be designed, structured, and strategically expanded. That shift is especially important in the age of generative AI, where broad model access is increasingly becoming normalized. If many companies can access strong base models, then the competitive advantage moves elsewhere. It moves toward proprietary workflows, domain expertise, and most importantly, data infrastructure.
Synthetic data becomes powerful in exactly this environment. It allows organizations to construct training and validation conditions that would otherwise be unavailable. Rather than being limited to whatever the world happened to generate, enterprises can proactively simulate the scenarios that matter. They can create controlled variations of lighting, weather, object pose, system failures, edge cases, behavioral patterns, rare combinations, and domain-specific situations that rarely appear in naturally collected datasets. This is particularly valuable in computer vision, industrial AI, robotics, healthcare modeling, security applications, and any setting where rare or sensitive data has disproportionate importance.
One reason synthetic data is re-emerging so strongly is that the industry is finally confronting the limits of web-scale data. Public internet data helped fuel the first major wave of foundation models, but enterprise AI has very different needs. Companies do not just need "more data." They need specific data. They need data aligned with their own products, internal processes, regulatory requirements, hardware environments, visual domains, customer interactions, and decision logic. A large corpus of generic online information may help train broad capabilities, but it does not automatically prepare an AI system to understand a company's manufacturing anomaly, insurance workflow, internal terminology, or digital twin simulation environment.
This is where synthetic data offers something much more valuable than scale alone: intentionality. It gives organizations the ability to create data with a purpose. Instead of inheriting biases, omissions, and randomness from external sources, they can define the conditions under which data should be generated. That does not mean synthetic data is automatically perfect or unbiased. It does mean that it can be shaped around clear objectives. This distinction matters. In AI development, randomness can be abundant, but relevance is scarce.
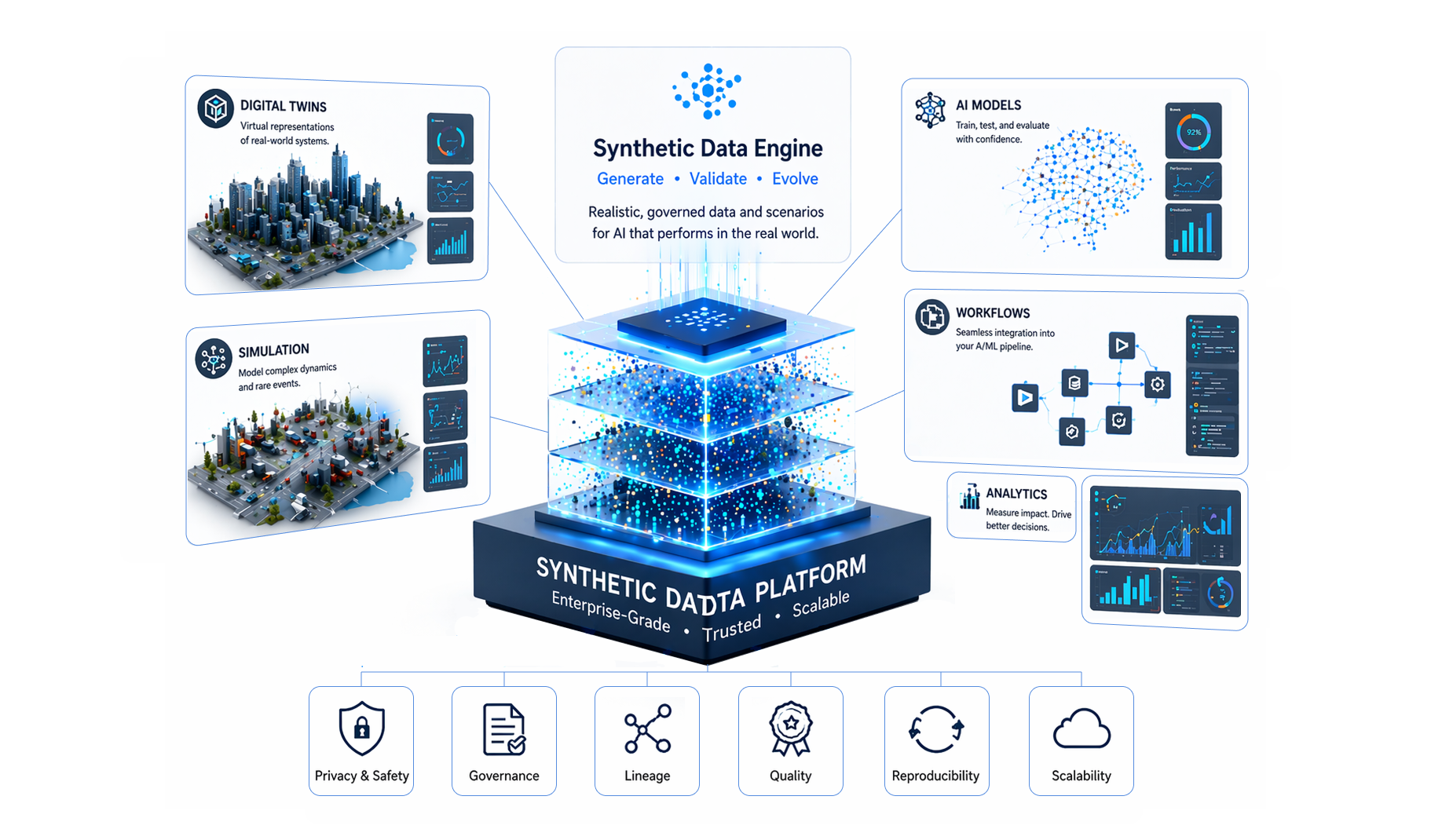
This renewed focus is also closely tied to the growing importance of AI governance. As generative AI has become a board-level topic, data provenance and policy compliance have become much harder to ignore. Organizations increasingly need to answer questions such as: Where did this training data come from? Does it include personally identifiable information? Is it safe to use across jurisdictions? Does it expose legal or contractual risks? Can it be audited? Can its origin be explained to customers, partners, or regulators? These questions matter even more in sectors such as healthcare, finance, manufacturing, and public infrastructure, where trust is not optional.
Synthetic data is often attractive in these settings because it can reduce direct exposure to sensitive real-world records while still preserving useful patterns, structures, or operating conditions. For example, privacy-preserving synthetic tabular data may support development without exposing raw personal information. Simulated industrial scenes may help train models for defect detection without requiring massive on-site capture campaigns. Artificially generated edge scenarios may help evaluate safety behavior without recreating dangerous real events. In each case, synthetic data acts as a bridge between practical need and operational constraint.
Another reason synthetic data is gaining attention is the long-tail problem. In production AI, average-case performance is rarely enough. Systems often fail not under normal conditions, but in rare, difficult, and operationally critical situations. A vision model may work perfectly in daylight but degrade sharply in glare, rain, fog, or partial occlusion. A robotics system may perform well in standard environments but fail during rare interactions between objects, surfaces, and motion. A digital inspection system may classify common defects accurately but miss unusual failure modes that have the greatest business impact. Real-world datasets are often dominated by ordinary cases, which means they systematically underrepresent exactly the events that matter most for robustness.
Synthetic data gives companies a mechanism to deliberately expand coverage in those blind spots. Rather than waiting years to naturally collect enough rare cases, they can simulate them now. Rather than treating anomalies as unfortunate data gaps, they can turn them into structured test conditions. This capability is especially important when AI systems are expected to operate in safety-critical, mission-critical, or high-cost environments. In such cases, training only on what is easy to collect can become a hidden liability.
At the same time, the growing role of simulation and digital twins has made synthetic data more practical and more valuable than before. Modern 3D tools, rendering pipelines, sensor simulation frameworks, physics engines, and scene-generation workflows make it possible to create controlled environments with a high degree of variability. This is not limited to creating "fake images." It includes building entire operational worlds where geometry, materials, camera positions, movement, environmental conditions, and event logic can be adjusted. The result is not merely a larger dataset, but a much richer experimental space.
This distinction is important. Traditional data augmentation expands data by modifying existing examples. Synthetic data generation, especially when supported by simulation or procedural pipelines, can create fundamentally new combinations and conditions. It can produce not just more of the same, but classes of scenarios that may not exist in the original dataset at all. This is why synthetic data is particularly relevant for tasks involving digital twins, autonomous systems, industrial monitoring, defense scenarios, smart infrastructure, and spatial AI.
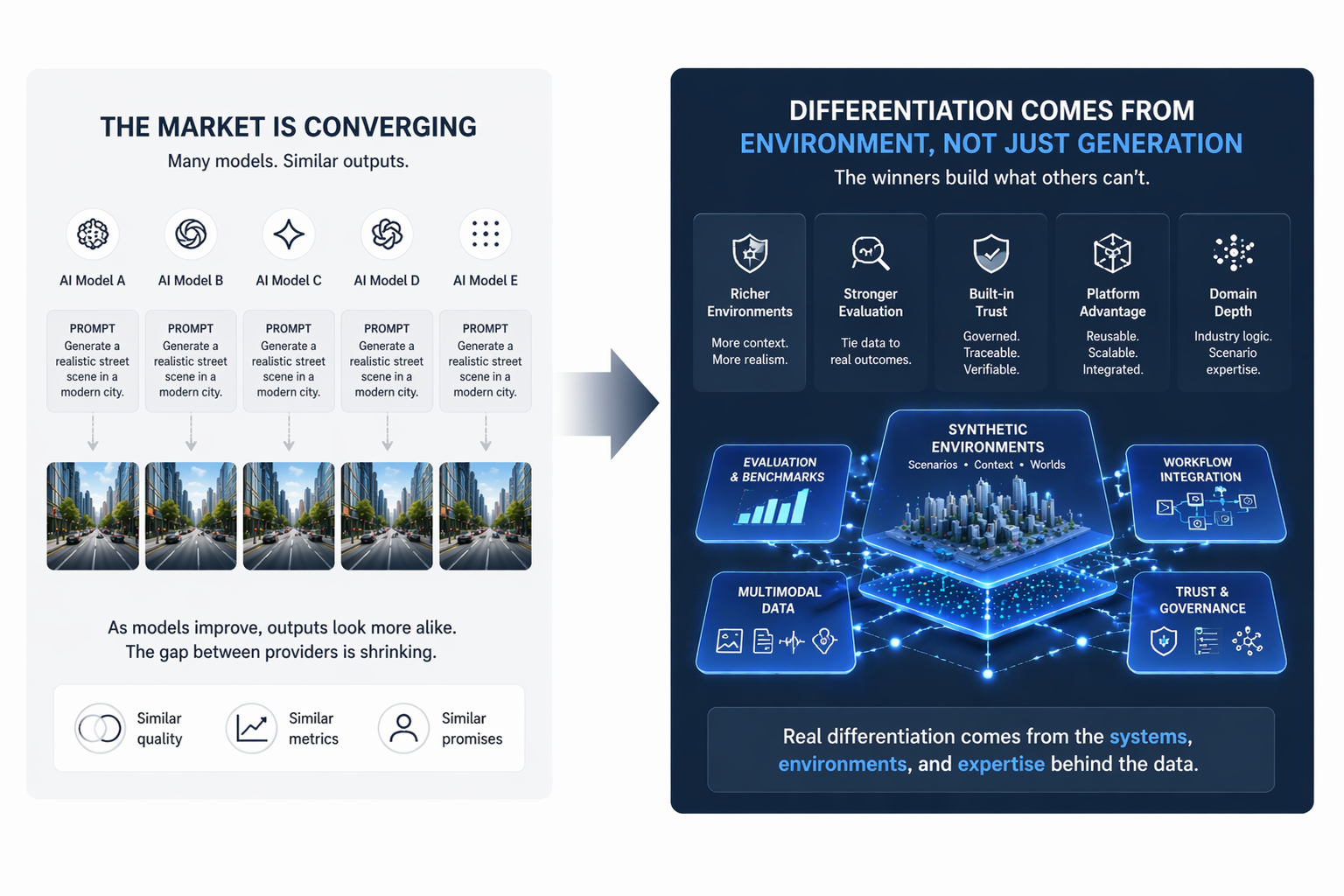
Of course, synthetic data is not a magical replacement for reality. A careless synthetic data strategy can generate visually impressive but operationally weak datasets. If generated samples fail to reflect real-world distributions, physical constraints, material properties, or context-specific patterns, the resulting model may learn shortcuts that do not generalize. This is why the conversation around synthetic data has matured. The most serious practitioners no longer treat it as a shortcut. They treat it as an engineering discipline. Quality synthetic data requires domain expertise, validation loops, and careful alignment with real deployment conditions.
The most effective organizations are not choosing between real data and synthetic data. They are building systems in which both work together. Real data provides grounding, authenticity, and distributional truth. Synthetic data provides scalability, balance, coverage, privacy control, and targeted experimentation. Used together, they make AI development more resilient. Real data can reveal what the world looks like; synthetic data can help prepare for what the world may eventually demand. This complementary relationship is one of the strongest reasons synthetic data is becoming part of the core conversation around enterprise AI infrastructure.
It is also becoming strategically important from a business perspective. As model access becomes easier and competition intensifies, data is becoming one of the few defensible layers in the AI stack. A company's ability to generate domain-specific scenarios, create private evaluation benchmarks, simulate edge cases, and continuously refine its training environment can become a meaningful source of competitive advantage. Unlike off-the-shelf models, these capabilities are deeply tied to internal know-how, workflows, and infrastructure. They are harder to copy and easier to compound over time.
Looking ahead, the enterprises that win with AI are unlikely to be the ones that simply consume the largest models. They will be the ones that understand how to build robust, governed, domain-aligned data ecosystems around those models. Synthetic data is becoming central to that effort because it gives organizations leverage where reality alone does not. It creates room for safe experimentation, faster iteration, broader coverage, and stronger preparation for operational complexity.
That is why synthetic data is gaining renewed attention in the age of generative AI. Not because the industry has lost faith in real data, but because it now understands more clearly where real data falls short. As organizations move from AI excitement to AI execution, synthetic data is emerging not as a niche topic, but as part of the foundational infrastructure that makes enterprise AI practical, scalable, and trustworthy.