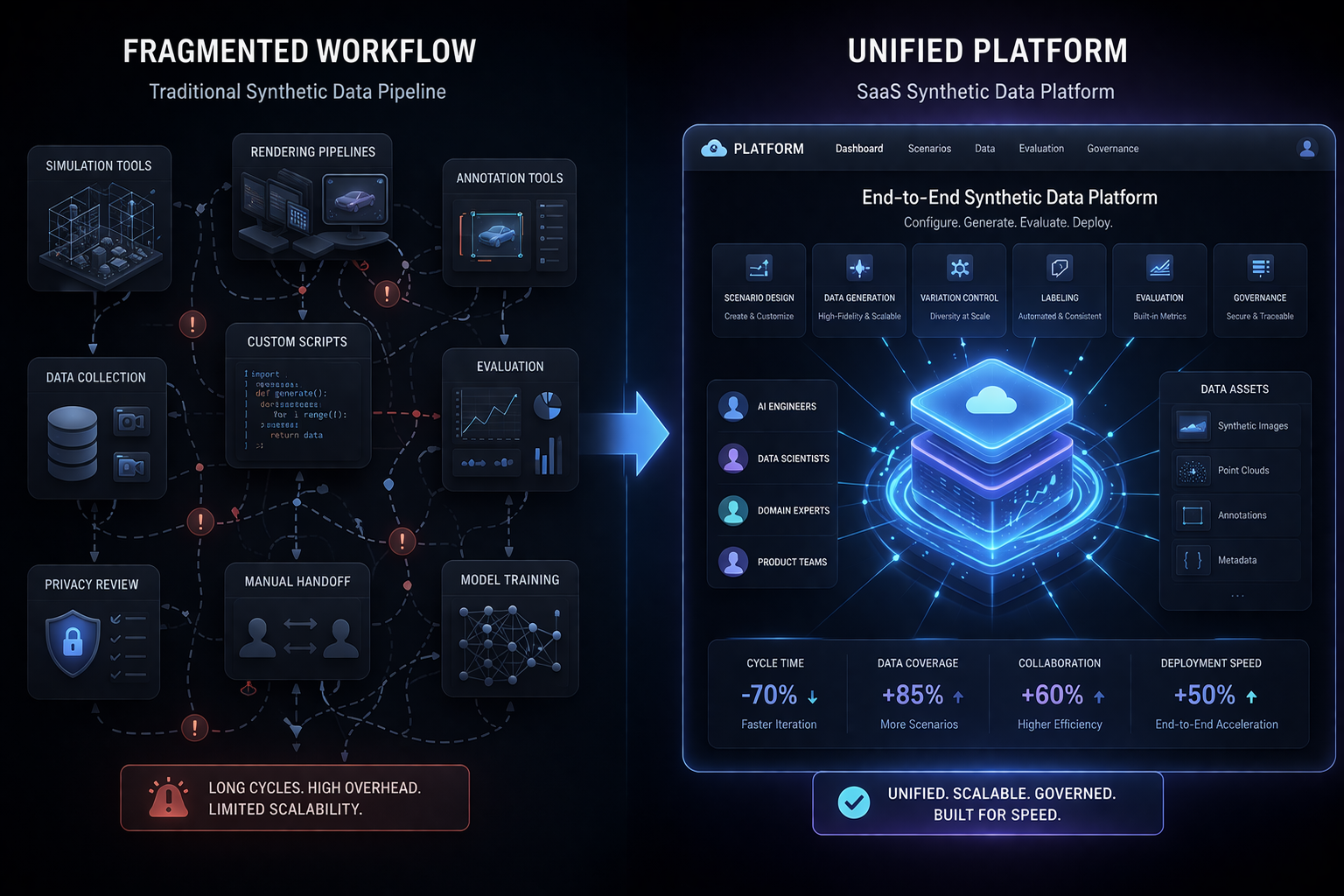
Vision AI systems have benefited significantly from synthetic image data over the past decade, but the way organizations approach synthetic generation has not always kept pace with the increasing complexity of what these systems are expected to do. Early uses of synthetic imagery were often straightforward: render enough objects in enough positions to teach a model basic detection or classification. That approach worked when tasks were simple and evaluation benchmarks were forgiving. As vision AI moves into more demanding real-world applications, a more strategic approach to synthetic image data becomes necessary.
The core challenge is that vision AI in production environments does not operate under controlled conditions. It encounters variable lighting, partial occlusion, sensor degradation, unfamiliar background contexts, unusual object configurations, weather effects, reflection, glare, distance variation, and many other sources of complexity that routine photography-based datasets do not capture systematically. If synthetic data is generated without deliberately targeting this breadth of environmental variation, the model may learn to recognize objects in idealized conditions but struggle in the messy reality of deployment. Strategic synthesis means designing generation pipelines that intentionally span the range of conditions the model will actually encounter.
One of the most important strategic decisions is how to balance photorealism against structured coverage. High-resolution photorealistic rendering has obvious appeal, and the visual quality of modern synthesis tools is impressive. But photorealism is not the same as operational relevance. A perfectly rendered image under ideal lighting conditions may be less useful for training a robust outdoor detection model than a moderately rendered scene captured under challenging fog, shadow, or lens distortion. The goal is not to produce images that look beautiful in isolation. the objective is to produce operationally meaningful coverage of the visual space the model will navigate in production.
This principle applies to how object attributes are varied in synthetic scenes. Strategic generation considers not just object identity but the full range of visual properties that affect recognition: scale, viewing angle, lighting intensity and color temperature, surface texture and material variation, partial occlusion by other objects or environmental elements, motion blur and depth-of-field effects, and background context that may interfere with feature extraction. When these dimensions are varied systematically rather than randomly, the resulting dataset teaches the model to handle variation rather than just memorize common configurations.
Domain gap management is another critical element of strategic synthetic image generation. The domain gap refers to the difference between the distribution of synthetic training images and the distribution of real images the model will encounter during deployment. If this gap is too large, models trained heavily on synthetic data will perform poorly in real environments even if they appear to perform well on synthetic benchmarks. Closing the domain gap requires careful attention to rendering conditions, camera parameter calibration, noise modeling, and the statistical properties of real sensor outputs. Teams that treat domain gap as an afterthought rather than a core design constraint often find that their synthetic pipeline produces data that is technically plentiful but practically unreliable.
One way to manage the domain gap more effectively is to use small amounts of real reference data as calibration anchors during synthesis. Even without large real datasets, a carefully selected set of reference images can be used to tune rendering parameters, validate scene composition, and evaluate whether synthetic examples match the statistical patterns of real-world inputs. This hybrid approach does not require large real-world datasets to be useful. It requires representative real examples that can serve as ground truth for calibration without being large enough to train on directly. This strategy is particularly valuable for organizations that have limited access to real data but can afford careful reference collection for calibration purposes.
familiar dataset assumptions can cause problems when deploying to new domains. Many teams build synthetic pipelines calibrated to one type of environment and then apply them to settings with meaningfully different visual characteristics. A pipeline calibrated for indoor manufacturing environments may not transfer well to outdoor logistics operations. A generation approach tuned for daylight object detection may fail to produce useful training data for low-light or thermal imaging applications. Strategic planning requires explicitly identifying the boundaries of the deployment domain and ensuring that the synthetic pipeline is calibrated to that domain rather than to a more convenient or familiar one.
Long-tail coverage is one of the most compelling arguments for strategic synthetic generation in vision AI. Real-world deployment consistently reveals that model failures cluster around uncommon visual configurations: unusual damage patterns, atypical object orientations, rare environmental combinations, unexpected background contexts. These tail cases are by definition underrepresented in standard data collection. Synthetic generation allows teams to deliberately focus production resources on tail scenarios rather than adding more redundant coverage of common cases. This targeted approach does not require generating millions of images. It requires generating the right hundreds or thousands of images that address structural gaps in coverage.
Evaluation strategy must also be designed strategically alongside the generation pipeline. Models trained on synthetic data should be evaluated in ways that directly measure transfer to real conditions rather than performance on held-out synthetic examples. This requires building realistic evaluation sets even in the absence of large real-world training datasets. If evaluation is done only on synthetic data, it creates a misleading signal that may not predict real deployment performance. The evaluation environment and the generation environment must be treated as separate problems with separate requirements.
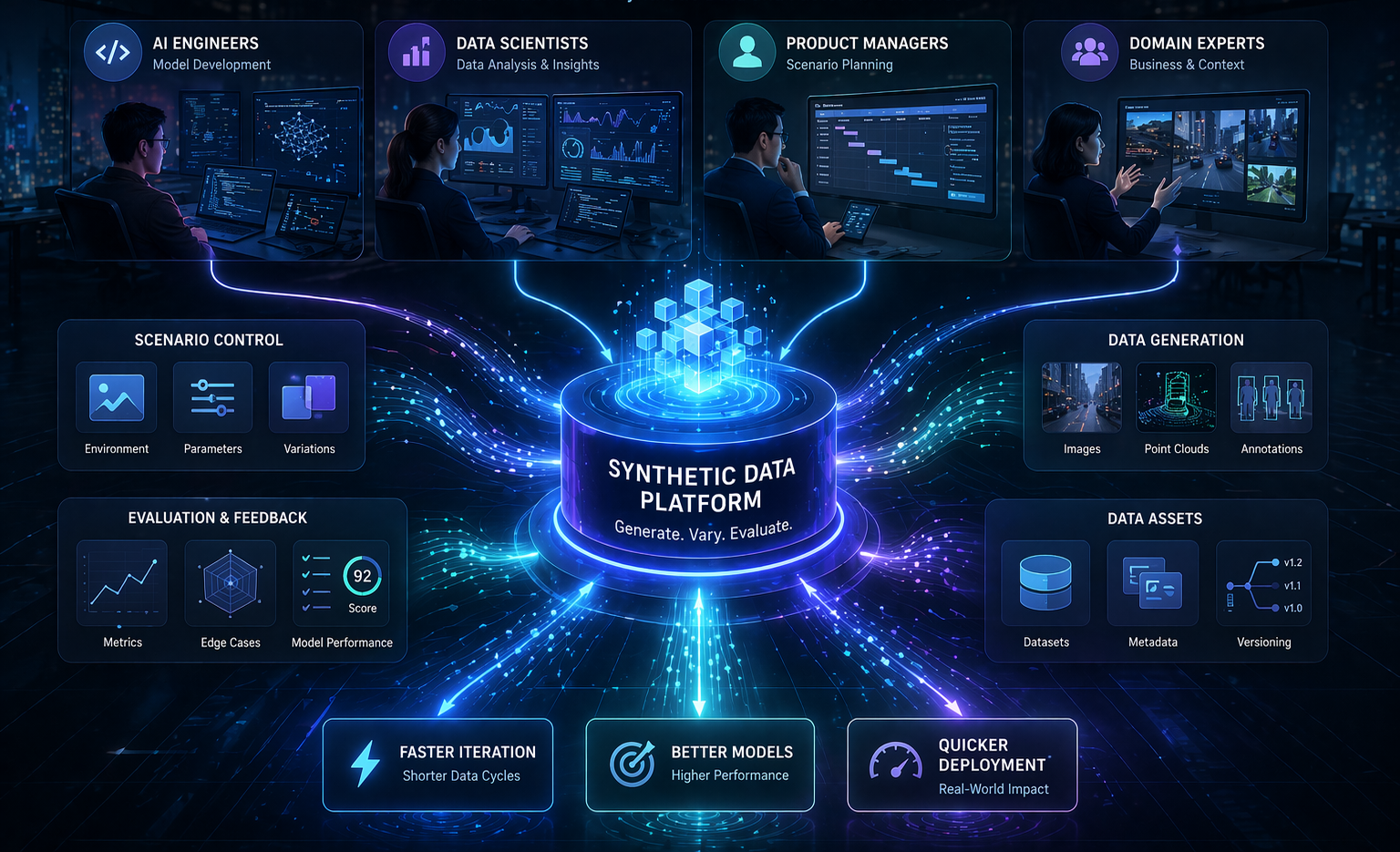
The most effective organizations using synthetic image data for advanced vision AI have moved beyond treating generation as a purely technical pipeline problem. They approach it as a strategic design problem: what visual conditions matter for deployment, how do we represent those conditions in a controlled generation environment, how do we calibrate that environment to minimize domain gap, and how do we evaluate transfer before committing to full-scale deployment. That design-first mindset is what distinguishes synthetic image pipelines that reliably improve real-world performance from those that produce impressive-looking datasets without meaningful operational impact.