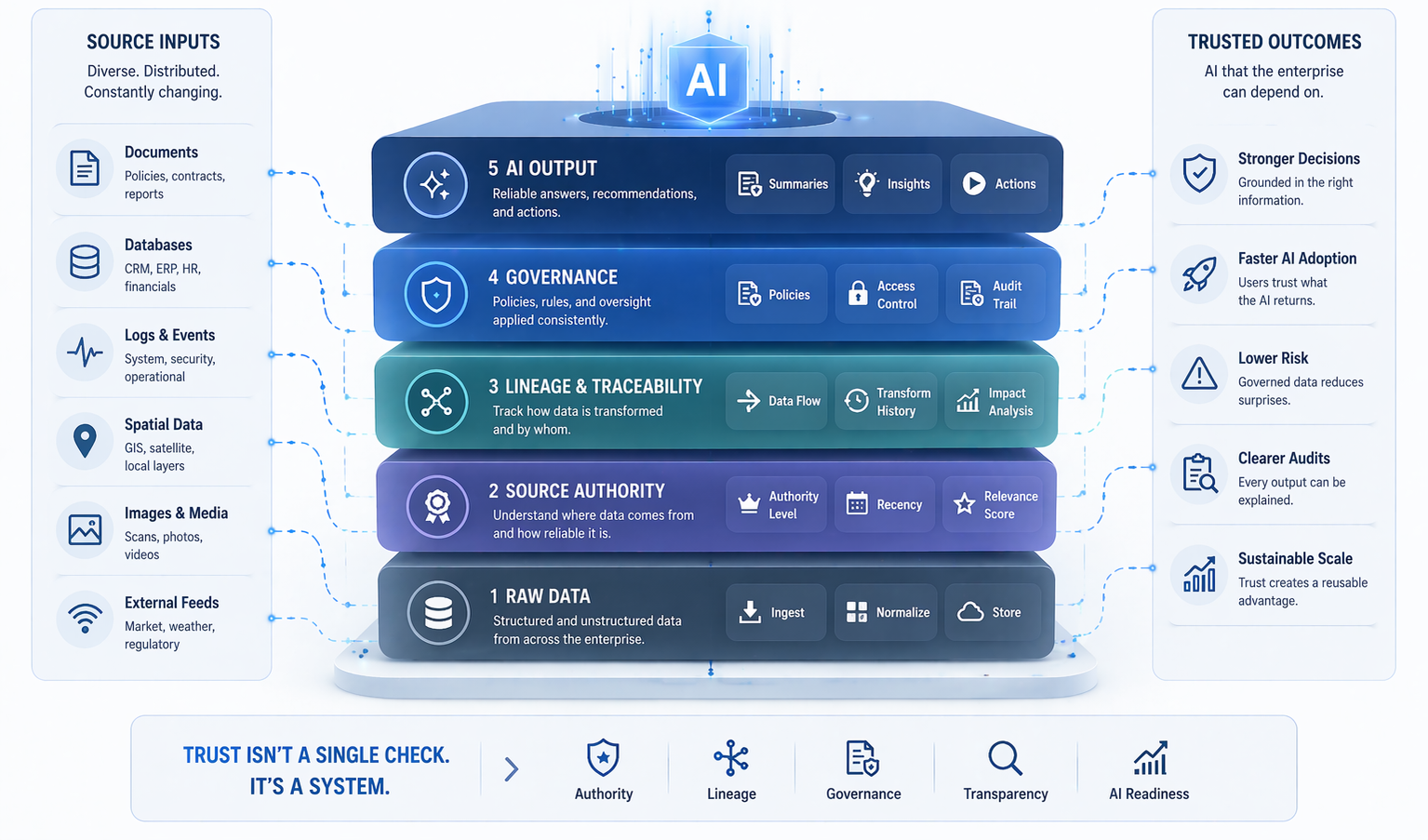
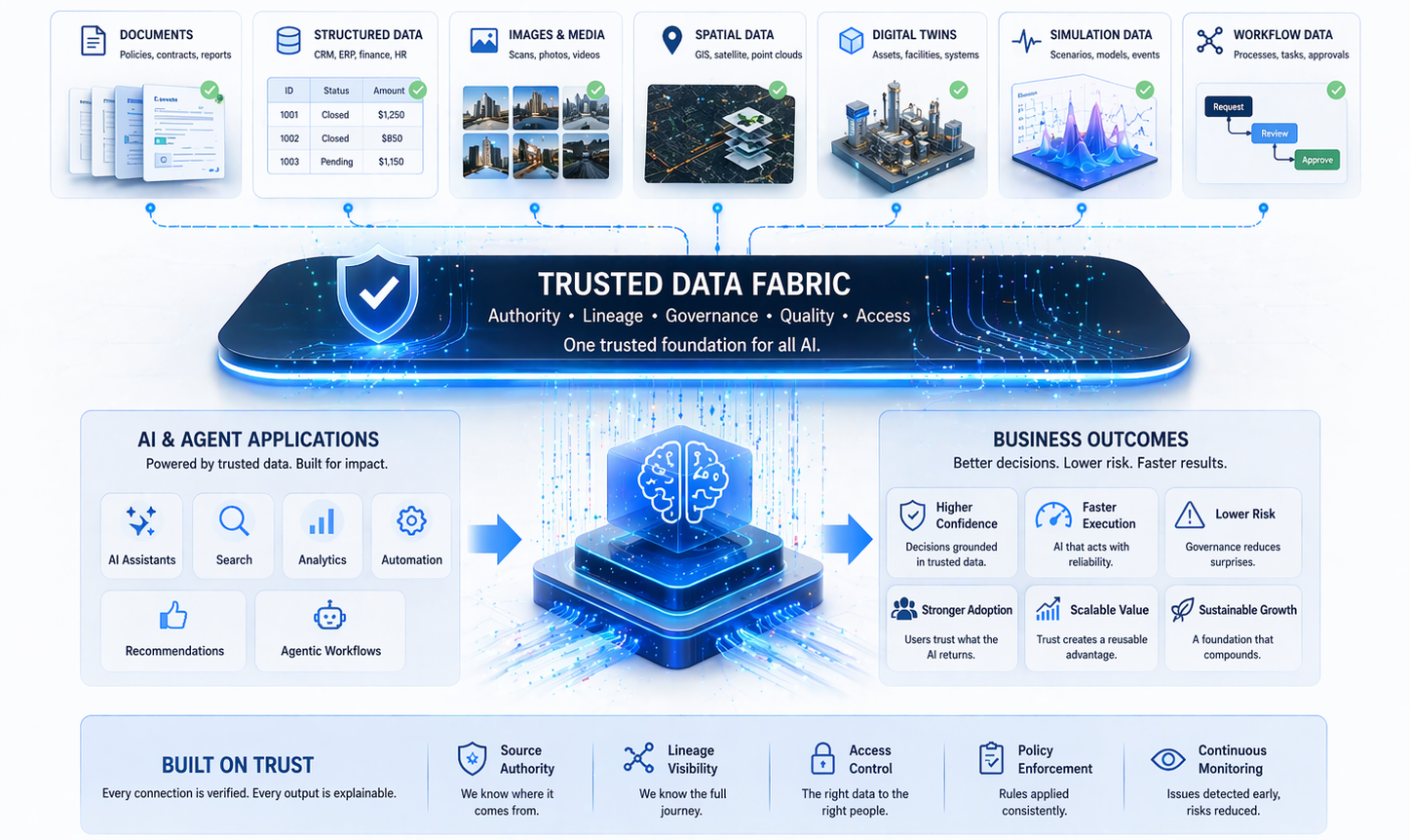
One of the biggest barriers to enterprise AI is not whether useful models exist. It is how long it takes to prepare the data those models need. Data collection, labeling, cleaning, and governance can consume months of a project timeline before a single meaningful training run occurs. SaaS synthetic data platforms are beginning to change this dynamic in ways that have significant implications for deployment speed.
The core value of a SaaS synthetic data platform is that it compresses the time between "we have a use case" and "we have training-ready data." Instead of relying solely on historical collection and manual annotation, teams can generate scenario-specific examples programmatically. They can fill coverage gaps, create rare-event datasets, and build evaluation sets without waiting for real-world conditions to produce the right examples. For use cases where specific conditions must be represented but rarely occur naturally, this is transformative.
Early adopters of these platforms report significant reductions in data preparation timelines. Projects that previously required four to six months of data collection before model development could begin are now reaching training-ready data states in weeks. This acceleration affects not just the initial deployment but also the iteration cycle. When a deployed model reveals a coverage gap, teams can generate targeted synthetic examples to address it quickly rather than waiting months for new real-world data to accumulate.
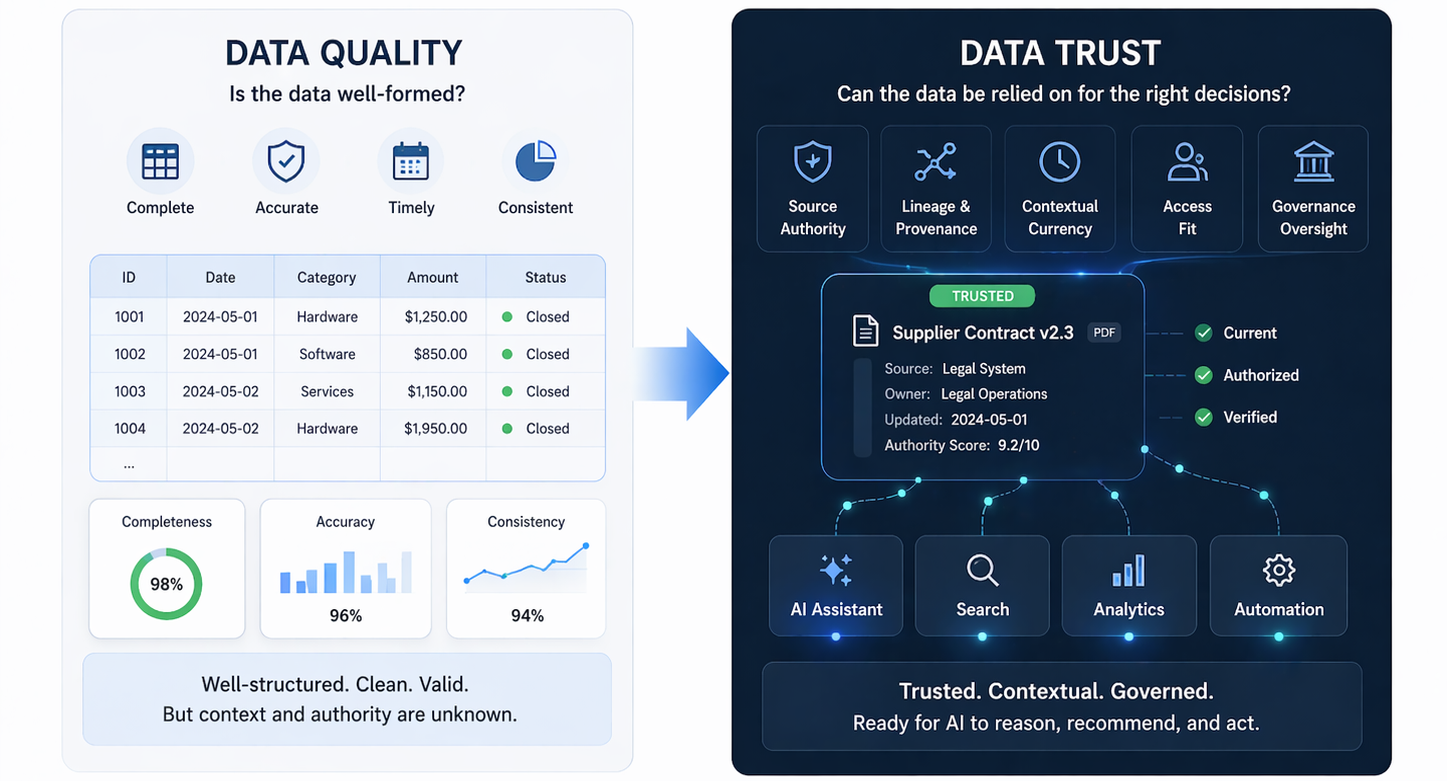
The quality controls built into modern synthetic data platforms have also improved substantially. Earlier synthetic generation tools often produced data that improved training volume but introduced distribution shifts that hurt real-world performance. Current platforms offer domain-specific generation engines, physical simulation layers, and statistical validation tools that help ensure synthetic examples are realistic enough to transfer. This has addressed one of the key objections enterprise buyers historically raised.
The SaaS model also changes the cost structure of synthetic data access. Previously, building synthetic data generation capabilities required significant internal engineering investment. SaaS delivery makes these capabilities accessible to teams that lack the resources to build them independently, broadening the market significantly and enabling a wider range of organizations to adopt AI at production scale.
What this means for enterprise AI strategy is that deployment speed is increasingly determined by data pipeline agility, not just model availability. Organizations that can generate high-quality synthetic data quickly have a structural speed advantage. Those still dependent on slow real-world collection cycles will find themselves consistently behind in iteration velocity. SaaS synthetic data platforms are not a niche tool for specialized teams. They are becoming a standard component of competitive enterprise AI infrastructure.