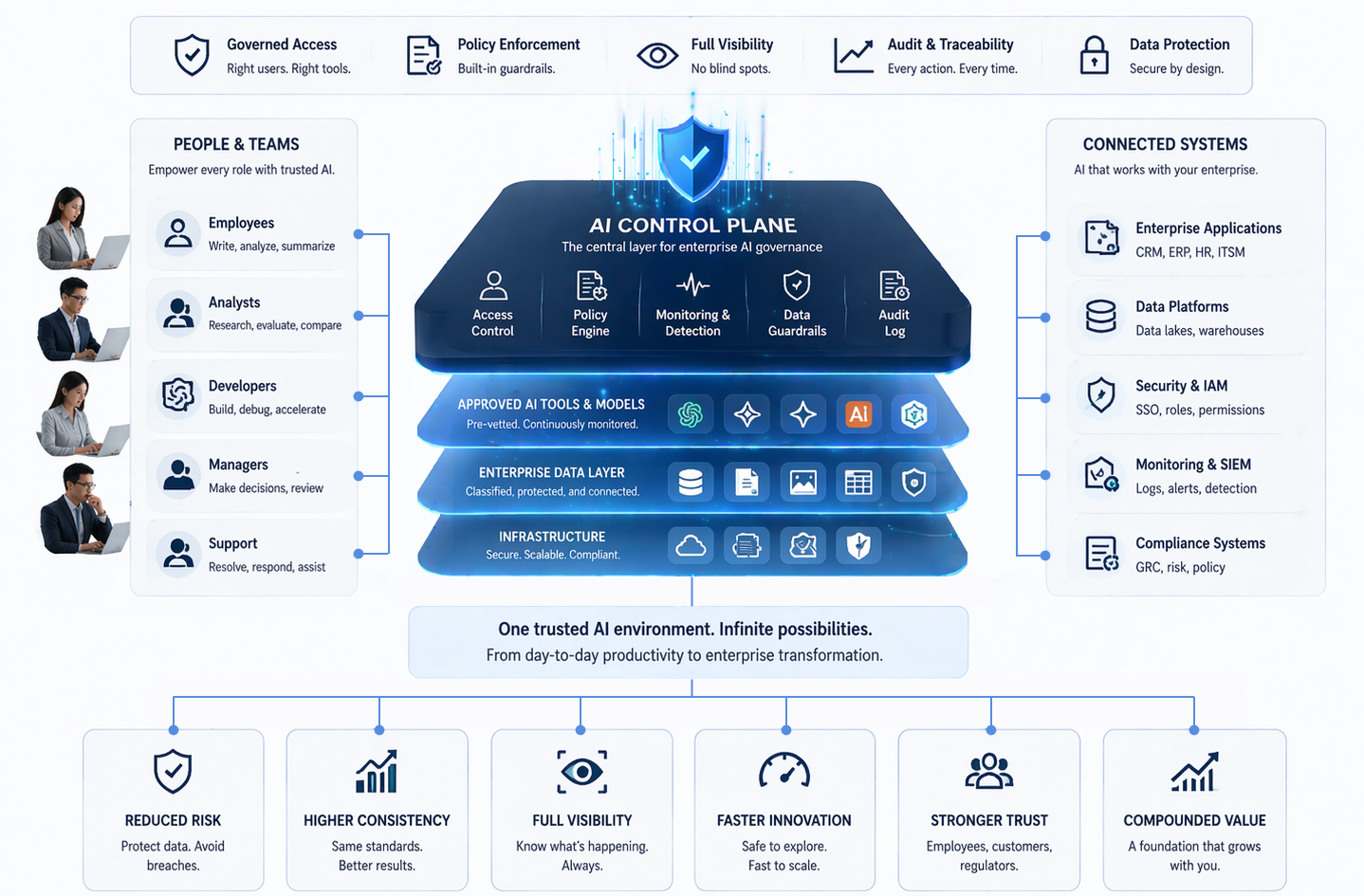
Large language models are often described in terms of scale. Larger pretraining corpora, larger compute budgets, longer context windows, and larger model architectures have all shaped the public narrative around LLM progress. This framing is not wrong, but it is incomplete. Once organizations move beyond experimentation and attempt to build dependable enterprise systems, they begin to discover that scale alone does not solve the hardest problems. The core issue is not simply how much data exists. It is whether the right data exists, whether it can be used safely, and whether it actually supports the kind of performance a production system requires.
At first, real data seems like the obvious foundation. It reflects the real world. It contains natural language, operational documents, actual user interactions, internal records, historical decisions, and contextual knowledge shaped by real workflows. It feels more trustworthy than anything artificially generated. In many ways, that instinct is valid. Real data is indispensable. It captures patterns that cannot be fully invented from scratch. It preserves authentic context, human phrasing, domain nuance, and the messy richness of real organizational life. Without real data, LLM systems risk becoming detached from the environments they are supposed to serve.
And yet, real data alone reaches clear limits. One of the most immediate limits is access. In enterprise settings, much of the most valuable language data is sensitive. Legal contracts, healthcare notes, financial documents, internal tickets, compliance records, customer support transcripts, design reviews, policy manuals, incident reports, and strategic communications often contain confidential or regulated information. Even when such content could significantly improve an LLM, organizations cannot always use it freely. Privacy law, confidentiality agreements, internal governance controls, security policies, and risk management practices all create friction. The result is that companies often possess highly relevant data but are unable to fully activate it for large-scale training or evaluation.
This limitation becomes even more serious when an organization wants not just to experiment with an LLM, but to rely on it in real work. A proof of concept may tolerate rough performance. A production system cannot. Once the model is expected to summarize documents accurately, answer internal questions consistently, generate compliant outputs, or assist employees in sensitive processes, the quality and appropriateness of its data foundation become central. Real data is helpful, but access constraints can leave crucial blind spots.
Another challenge is imbalance. Real-world language data is not produced for model development. It emerges from human activity, which means it reflects the habits, omissions, and unevenness of actual work. Some topics are documented extensively. Others are barely documented at all. Common tasks generate massive textual footprints, while rare but high-risk situations may leave very few usable examples. In a business context, this creates an important problem. Models may become relatively strong at ordinary queries while remaining weak on exceptions, escalation paths, ambiguous instructions, or policy-sensitive cases. Unfortunately, these are often exactly the places where performance matters most.
For example, an internal AI assistant may see thousands of examples of routine HR, IT, or documentation questions, but very few carefully validated examples of edge-case compliance handling, contract interpretation boundaries, or critical escalation logic. A model trained only on naturally available enterprise data may therefore appear capable while still failing under pressure. This creates a false sense of readiness. The model seems helpful during normal usage but becomes unreliable in the most consequential situations.
A third issue is quality inconsistency. Real enterprise data is often fragmented, duplicated, outdated, and contradictory. Documents may have multiple versions. Policies may conflict across departments. Terminology may vary between teams. Historical records may reflect practices that are no longer valid. Informal communication may contain incomplete reasoning, shorthand, or misleading assumptions. This kind of data is unavoidable in real organizations, but it creates substantial challenges for LLM training and retrieval pipelines. A model does not merely absorb facts; it absorbs structures, styles, associations, and decision tendencies. If the source environment is noisy, the resulting outputs may be noisy in ways that are difficult to detect until they cause real harm.
This is especially problematic because LLM errors are often plausible. A model trained on inconsistent internal data may produce outputs that sound confident and well-formed while being subtly wrong. In enterprise settings, subtle errors can be more dangerous than obvious failures. They can affect customer communication, policy interpretation, operational recommendations, or compliance decisions. Real data provides realism, but realism by itself does not guarantee suitability.
There is also a representational problem. Enterprises often expect LLMs to perform tasks that go beyond what their organic language data naturally supports. They want models to answer in consistent formats, follow controlled reasoning paths, produce role-specific responses, respect internal tone guidelines, incorporate policy constraints, and behave predictably across multiple departments. However, most real data was not written with these objectives in mind. It was created by humans solving immediate problems. As a result, the data may reflect organizational knowledge without being structured in a way that supports consistent model behavior.

This is where synthetic, structured, and scenario-designed data becomes important. In the LLM context, synthetic data does not have to mean unrealistic or invented content detached from business needs. It can include carefully generated instruction-response pairs, simulated internal workflows, multilingual rewrites, policy-grounded Q&A sets, edge-case scenario prompts, controlled task variations, or evaluation examples built to stress-test specific capabilities. These forms of synthetic data help fill the gaps left by naturally occurring text.
For example, suppose an enterprise has strong documentation for normal workflows but almost no explicit examples of exception handling. Synthetic scenario generation can create targeted cases involving deadline conflicts, policy ambiguity, sensitive customer language, or escalation boundaries. Suppose another company wants to test whether its internal assistant can distinguish between informational guidance and legally binding advice. It can create synthetic evaluation prompts that systematically explore that boundary. In both cases, the purpose of synthetic data is not to replace real organizational knowledge. It is to make that knowledge operationally usable.
Synthetic data also helps solve the problem of balance. If real datasets overrepresent frequent tasks and underrepresent rare or sensitive ones, synthetic generation can rebalance the training and evaluation space. This is especially useful for aligning models to enterprise policies, testing multilingual consistency, and preparing systems for long-tail scenarios that may not appear often enough in historical records. By doing so, organizations move from passively inheriting data distributions to actively shaping them.
Another major advantage is privacy and governance. In many enterprises, one of the hardest barriers to LLM adoption is the fear that internal information may leak, be mishandled, or become entangled with systems in uncontrolled ways. Synthetic data can help reduce that risk by creating safe substitutes for certain development tasks. Instead of exposing raw sensitive records during early experimentation, teams can work with synthetic variants that preserve task structure without revealing confidential details. This does not eliminate governance requirements, but it creates a safer path for prototyping, benchmarking, and controlled iteration.
There is also a broader strategic point. LLM performance depends not only on knowledge, but on preparation. A well-performing enterprise model must be able to handle instructions, ambiguity, formatting, exceptions, organizational tone, and boundary conditions. Real data provides the world as it happened. Synthetic and structured data provide the world as the enterprise needs the model to understand it. This difference is subtle but critical. One is historical. The other is intentional. Robust LLM systems require both.
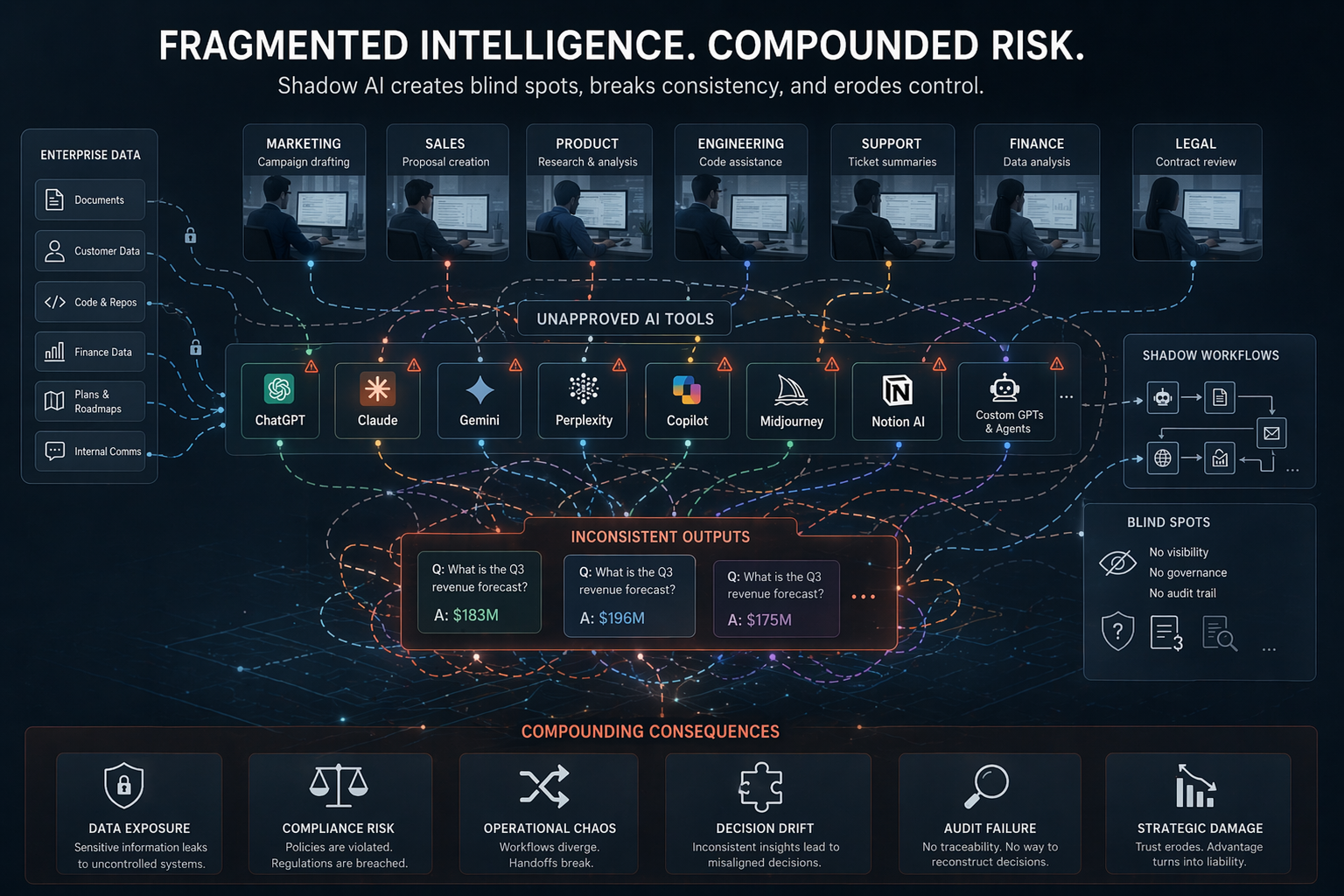
Importantly, this does not imply that synthetic data should dominate the pipeline. Overreliance on low-quality generated data can introduce artifacts, distort task distributions, and make models overly sensitive to generated phrasing patterns. That is why the strongest strategy is hybrid. Real data anchors the model in authentic language, actual business context, and true operational relevance. Synthetic data expands coverage, improves balance, creates safety buffers, and enables targeted testing. Structured curation then helps translate both into a usable system.
The enterprises that succeed with LLM deployment will likely be those that stop thinking about data as a raw stockpile and start thinking about it as an architecture. They will ask not only what data they have, but what data they lack, what conditions they cannot observe directly, what edge cases they have not covered, what risks they need to test, and what forms of behavior they need the model to internalize. This is a much more mature way of approaching AI development. It treats data not as a passive inheritance, but as something that must be designed around outcomes.
In that sense, the limit of real data is not that it is unimportant. Its limit is that it reflects reality in all its fragmentation, inconsistency, privacy constraints, and operational unevenness. Reality is essential, but reality alone is not enough. Enterprise LLMs need grounded authenticity, but they also need balance, control, testability, and safe abstraction. Synthetic and structured data provide those additional dimensions.
That is the deeper reason real data alone reaches its limits in LLM training. The issue is not whether real data matters. It absolutely does. The issue is that the enterprise environments where LLMs must perform are too sensitive, too uneven, and too complex to rely on raw reality alone. The future of strong LLM systems will belong to organizations that know how to combine authentic real-world context with intentionally designed data layers that make reliability possible.