When AI adoption accelerated in 2023, the first wave of attention focused heavily on what the new models could do. That focus made sense. Systems that had once seemed experimental suddenly appeared capable of reshaping writing, search, customer support, design, analysis, and automation. For many organizations, the first instinct was to ask how these systems could be connected to existing business data and processes as quickly as possible. But once practical implementation began, many teams encountered the same set of obstacles: privacy constraints, scarcity of the most important cases, and the unexpectedly high cost of turning real-world data into usable AI assets.
These three pressures had always existed in some form, but 2023 gave them a new level of urgency. The reason is that generative AI and large-model workflows dramatically increased the number of organizations trying to operationalize intelligence. Suddenly, far more teams needed training data, evaluation data, retrieval-ready content, or scenario-specific examples. And just as suddenly, they discovered that real-world data was not nearly as easy to use as it looked from a distance.
Privacy was the most immediate pressure point for many enterprises. Sensitive information had always required care, but AI changed the way that risk was perceived. A traditional reporting workflow might access private data in a controlled, narrow, and well-understood way. An AI workflow could potentially summarize, recombine, interpret, or generate from that same information in ways that felt much less predictable. This made many organizations more cautious. Internal records, customer interactions, financial histories, healthcare notes, support tickets, and operational documents all became harder to use casually because the system interacting with them was more dynamic than previous tools.
This issue was especially sharp in industries built on trust. Healthcare, finance, insurance, and enterprise services all rely on information that is valuable precisely because it is sensitive. That sensitivity is not a secondary inconvenience. It is often central to the business itself. In 2023, as these sectors explored AI more seriously, many discovered that privacy was not just a governance layer around AI. It was one of the central constraints shaping what types of AI experimentation were actually possible.
But privacy was only part of the problem. Scarcity was equally important, especially when organizations moved from generic AI demos toward domain-specific performance goals. The data required to make a system truly robust was often the data least available in useful quantity. Rare anomalies, unusual customer behaviors, critical exception cases, dangerous operational states, infrequent diagnosis patterns, and high-impact but low-frequency events are all examples of data categories that matter far more than their raw volume would suggest. Yet naturally collected data tends to underrepresent them.
This made many enterprises realize that their data challenge was not one of total absence. It was one of imbalance. They often had large amounts of ordinary information and very little of the information that would matter most for safe or differentiated AI performance. In a customer support system, that might mean not having enough examples of escalated policy-sensitive interactions. In manufacturing, it might mean lacking rare defect patterns. In finance, it might mean insufficient coverage of unusual fraud scenarios. In healthcare, it might mean very limited examples of uncommon but clinically important pathways. Scarcity, in this sense, was not about being data-poor. It was about being unevenly data-rich.
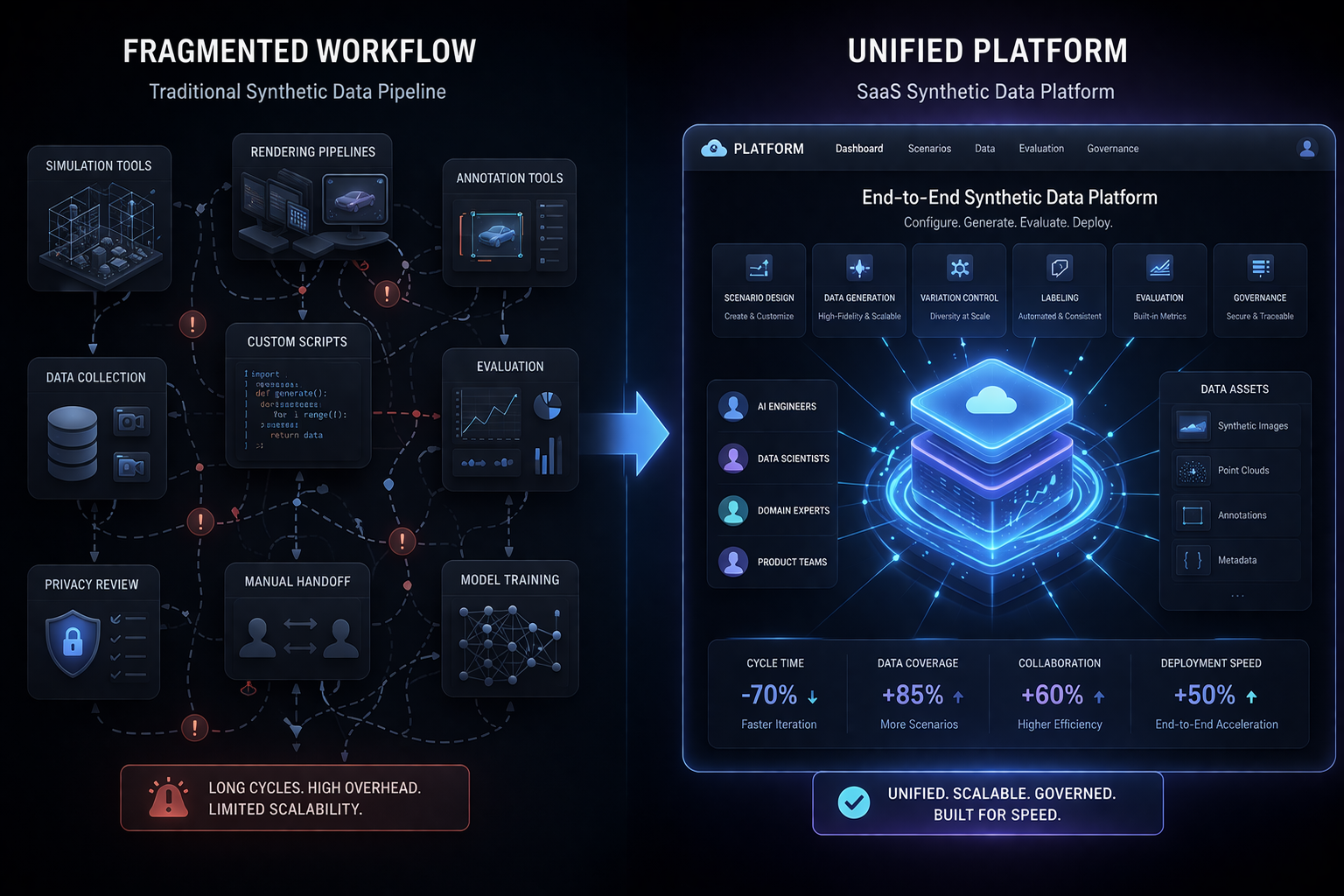
Cost then made the problem even harder. Even when useful real-world data existed and could legally be accessed, preparing it for AI was rarely simple. Records needed cleaning. Sensitive details needed masking or restructuring. Labels needed expert interpretation. Different systems needed normalization. Rare cases needed identification. Approval pathways needed to be navigated. Internal teams needed to align around what could be used, how it could be used, and whether it was actually fit for purpose. These are expensive processes. They consume time, people, and organizational attention. In 2023, many companies learned that the cost of preparing real data for serious AI development was often far higher than expected.
This changed the economics of enterprise AI. It meant that even if models became cheaper or easier to access, the cost of making them genuinely useful could still remain high because the real bottleneck lived in the data environment. A company could have access to strong language models and still be unable to deploy effectively because its internal content was too sensitive, too inconsistent, too narrow, or too costly to prepare in the right way. This was a major shift in perspective for many teams. The challenge was no longer only technological. It was structural.
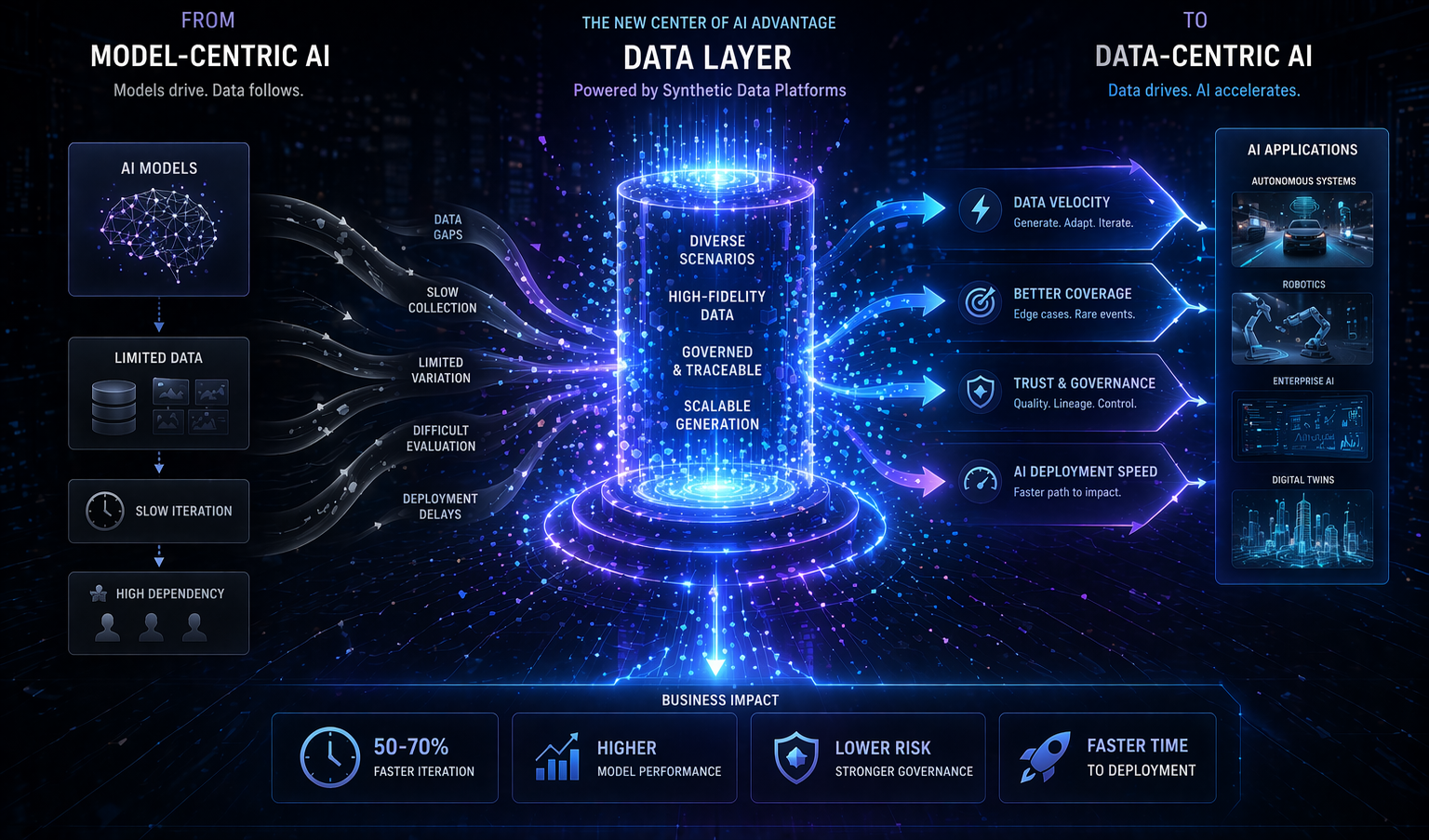
This is exactly why 2023 became such an important year for rethinking training data. Organizations began realizing that relying only on naturally collected real-world data might not be a sustainable long-term strategy. That does not mean real data lost value. It remained essential for grounding models in actual operational conditions. But it did mean that enterprises needed additional ways to build the data environments their AI systems required. They needed safer ways to test ideas, faster ways to create coverage, and more flexible ways to represent important but hard-to-capture conditions.
Synthetic data became more relevant in this context because it addressed all three pressures in different ways. It could reduce direct dependence on sensitive source material in the early stages of experimentation. It could create more deliberate coverage for rare or underrepresented situations. It could lower some of the costs associated with repeated collection and labeling loops. Most importantly, it gave organizations a way to design data where reality alone was too restrictive, too slow, or too costly.
This was not just a technical benefit. It was a strategic one. The ability to rethink training data meant the ability to move forward even when traditional data acquisition was blocked. It meant a team could continue prototyping without exposing raw customer records too broadly. It meant a product group could build evaluation cases before enough real failures had occurred. It meant a startup could accelerate its workflow without waiting for months of historical coverage to accumulate. In 2023, this flexibility became increasingly valuable.
Another important consequence is that enterprises began to understand data strategy more broadly. The goal was no longer just to gather as much real data as possible. The goal was to create the right combination of realism, safety, coverage, and practicality for the specific AI system being built. This is a more sophisticated view of training data. It recognizes that different use cases have different constraints, and that good data strategy is often about balance rather than purity.
There was also a governance advantage in this rethink. If teams could work with transformed, synthetic, or scenario-designed data earlier in the lifecycle, then experimentation could happen under lower-risk conditions. That did not eliminate the need for review, but it changed the intensity of the exposure problem in early phases. For many enterprises, that shift mattered enormously because it gave AI teams room to learn before confronting the full burden of production-grade data handling.
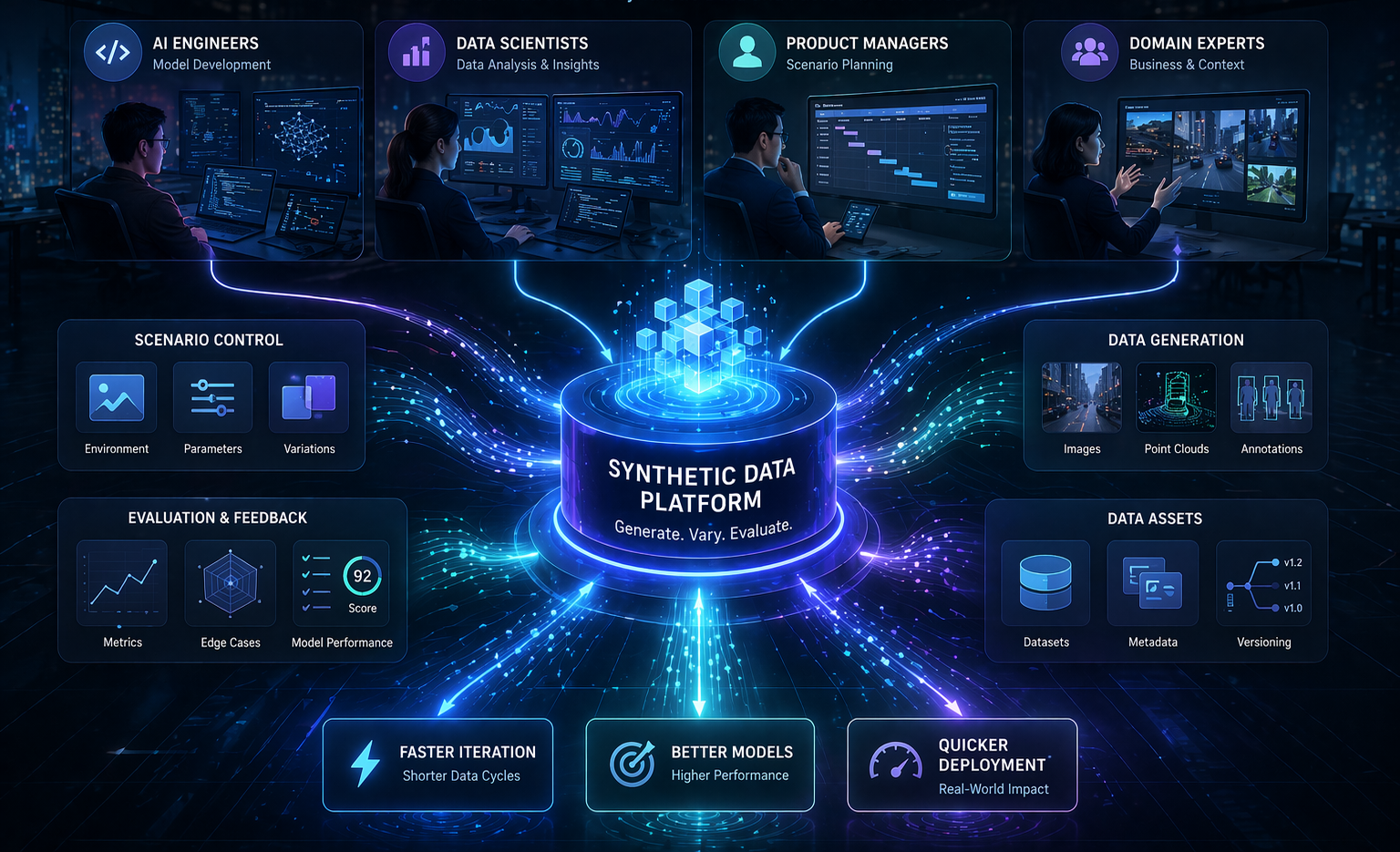
Of course, no serious organization in 2023 could treat synthetic or designed data as a perfect substitute for reality. Real data remained the final grounding layer. But the idea that "real-world data alone is enough" became much harder to defend. Privacy, scarcity, and cost had shown that the market needed something more flexible. Not less discipline, but more design.
This may be one of the most important lessons of that year. AI was not blocked because models were too weak. It was often blocked because the data systems around those models had not been built for the kind of intelligence companies were now trying to deploy. Privacy, scarcity, and cost made that clear. They forced the market to move from naive data assumptions toward more deliberate data architecture.
Ultimately, these three forces pushed enterprises to rethink training data because they exposed the limits of passive dependence on reality. A useful AI system needs real-world grounding, but it also needs preparation, coverage, and controlled experimentation. In 2023, more organizations began to understand that this combination would require new data strategies rather than old assumptions.
That is why privacy, scarcity, and cost became so important in 2023. They were not just constraints around AI. They were the pressures that forced enterprises to confront what kind of data environment would actually be needed to make AI practical, scalable, and safe in the years ahead.