Data scarcity is one of the most common and frustrating blockers in applied AI development. Organizations often have access to some real-world data, but not nearly enough to build reliable models for the specific conditions they care about. The gap between "we have data" and "we have sufficient data for this task" is wider than most teams anticipate. Synthetic data has emerged as a practical answer to this gap, but only when it is tailored carefully to the specific structure of the problem rather than generated in bulk without strategic intent.
The challenge with most scarcity problems is that they are not uniformly distributed. A dataset may have thousands of examples of ordinary cases but almost none of the rare events, edge conditions, or variant environments that matter most for robust performance. This kind of scarcity is harder to address than a simple lack of volume, because adding more generic data does not solve it. What is needed is targeted generation: creating examples specifically for the cases that are underrepresented, difficult to capture, or structurally important to model behavior. That is the core idea behind tailored synthetic data.
The first step in addressing data scarcity with synthetic generation is to characterize where the gaps actually are. This requires more than counting examples. It requires understanding what kinds of inputs the model will encounter during deployment, what distribution of conditions matters for performance, and which subsets of that distribution are not adequately covered by existing data. Teams that skip this diagnostic step often generate synthetic data that fills the wrong spaces. They increase volume without improving coverage. The result is a false sense of data adequacy that may only be revealed when the model encounters real conditions it was never trained to handle.
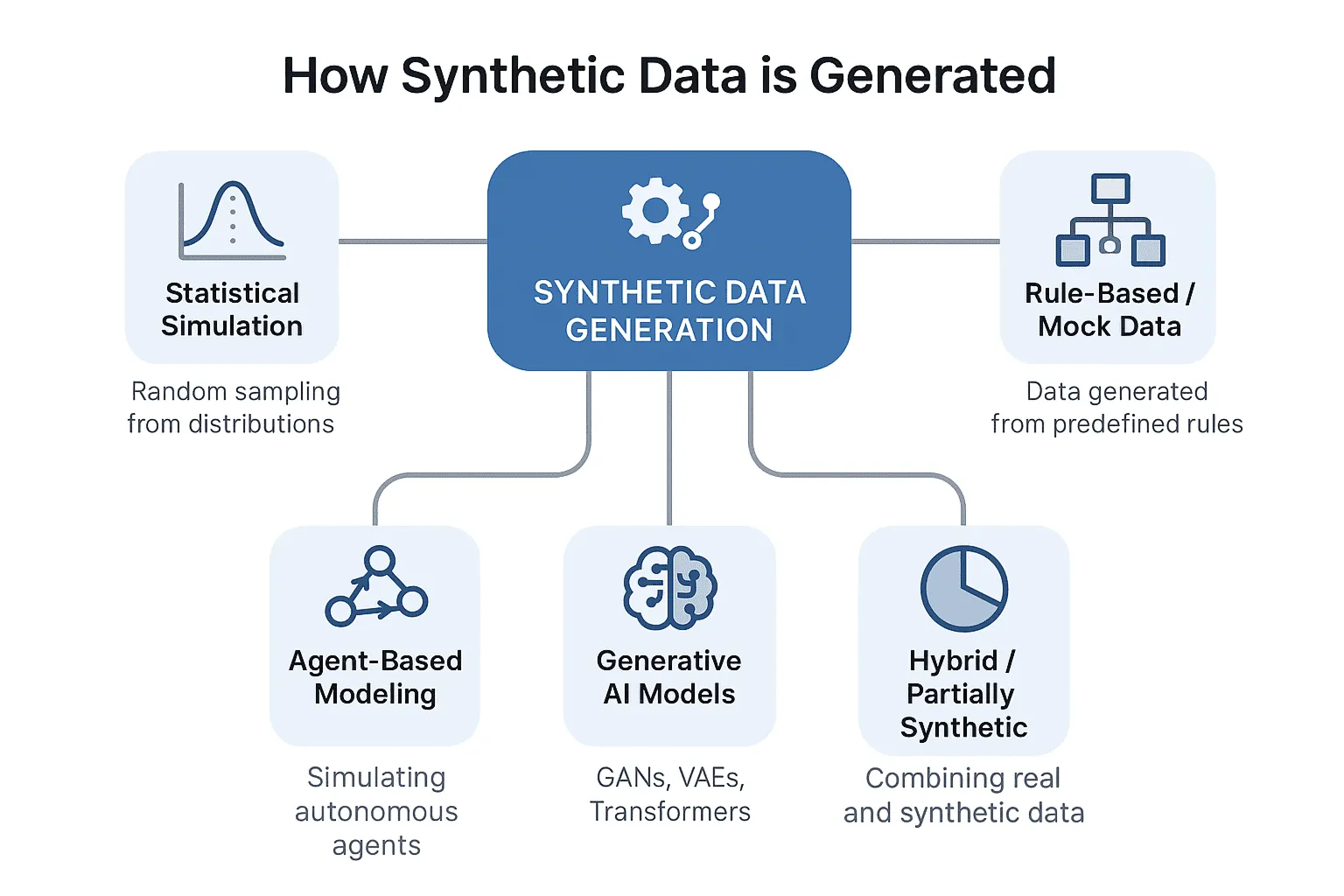
Once the scarcity structure is mapped, generation can be targeted. For vision models, this might mean creating more examples under challenging lighting, unusual occlusion patterns, atypical object poses, or rare damage signatures. For language models, this might mean generating task-relevant conversations, documents, or annotation examples that represent domain-specific vocabulary, ambiguous phrasing, or professional reasoning patterns not common in public datasets. For tabular systems, it might mean using controlled synthesis to fill in rare combinations of feature values that appear too infrequently in historical records. In all cases, the principle is the same: generate data that addresses a specific structural weakness rather than inflating overall size.
scarcity of task-specific usefulness is also a quality problem. Even when large volumes of real data exist, a surprising portion of it may be poorly labeled, misaligned with the actual deployment task, redundant across many nearly identical examples, or captured under conditions that do not reflect the environment where the system will be used. Synthetic data can help here too, not by adding more raw volume, but by introducing structured examples with cleaner labels, more consistent quality standards, and greater environmental diversity. In this sense, synthetic generation is not just about filling empty spaces. It is about improving the shape of the data landscape.
One important practical consideration is that synthetic data does not always need to dominate the training set to be useful. In many real-world applications, a small number of well-designed synthetic examples can have a disproportionate impact. If a model consistently fails on a narrow category of input and a few hundred synthetic examples correctly represent that category, performance can improve significantly. This is one reason why thinking about synthetic data in terms of targeted contribution rather than wholesale replacement of real data is often more productive.
Another consideration is the feedback loop between data generation and evaluation. When synthetic data is used to address scarcity, evaluation becomes more important, not less. If the gap between synthetic and real distributions is not carefully monitored, the model may learn to perform well on generated examples while still failing on the real ones that were missing. The evaluation conditions must reflect real deployment environments, not just the synthetic environment that was used for training. Building separate evaluation sets with real examples from the scarce categories, even small ones, is an important safeguard.
evaluation conditions are also worth examining when deciding which generation method to use. Some synthesis approaches produce high visual or statistical fidelity but at the cost of diversity. Others introduce more variation but with less precision. The right balance depends on what kind of coverage the model needs. For safety-critical applications, where the model must handle rare but consequential events reliably, precision in representing the rare event matters more than distributional diversity. For general-purpose systems that need robustness across a wide range of conditions, diversity may be more important.
Tailored synthetic data also changes how organizations think about their data supply chain over time. Rather than treating data collection as a one-time or periodic activity, teams that invest in synthetic generation capabilities can build a more continuous development loop. As deployment surfaces new weaknesses, those weaknesses can be characterized, translated into synthesis parameters, and addressed without waiting months for real-world collection campaigns. This responsiveness is particularly valuable in fast-moving domains where product requirements change frequently or where the deployment environment is variable and hard to predict in advance.
The practical path forward for organizations dealing with data scarcity is to start with clear documentation of where the scarcity actually lives. Build the diagnostic layer before the generation layer. Identify which failure modes in your current model trace back to underrepresented or structurally absent data, and design synthetic generation to address those specific problems. This is not the fastest or most superficially impressive use of synthetic data, but it is the most reliable way to ensure that the data you generate actually improves the AI you are building.