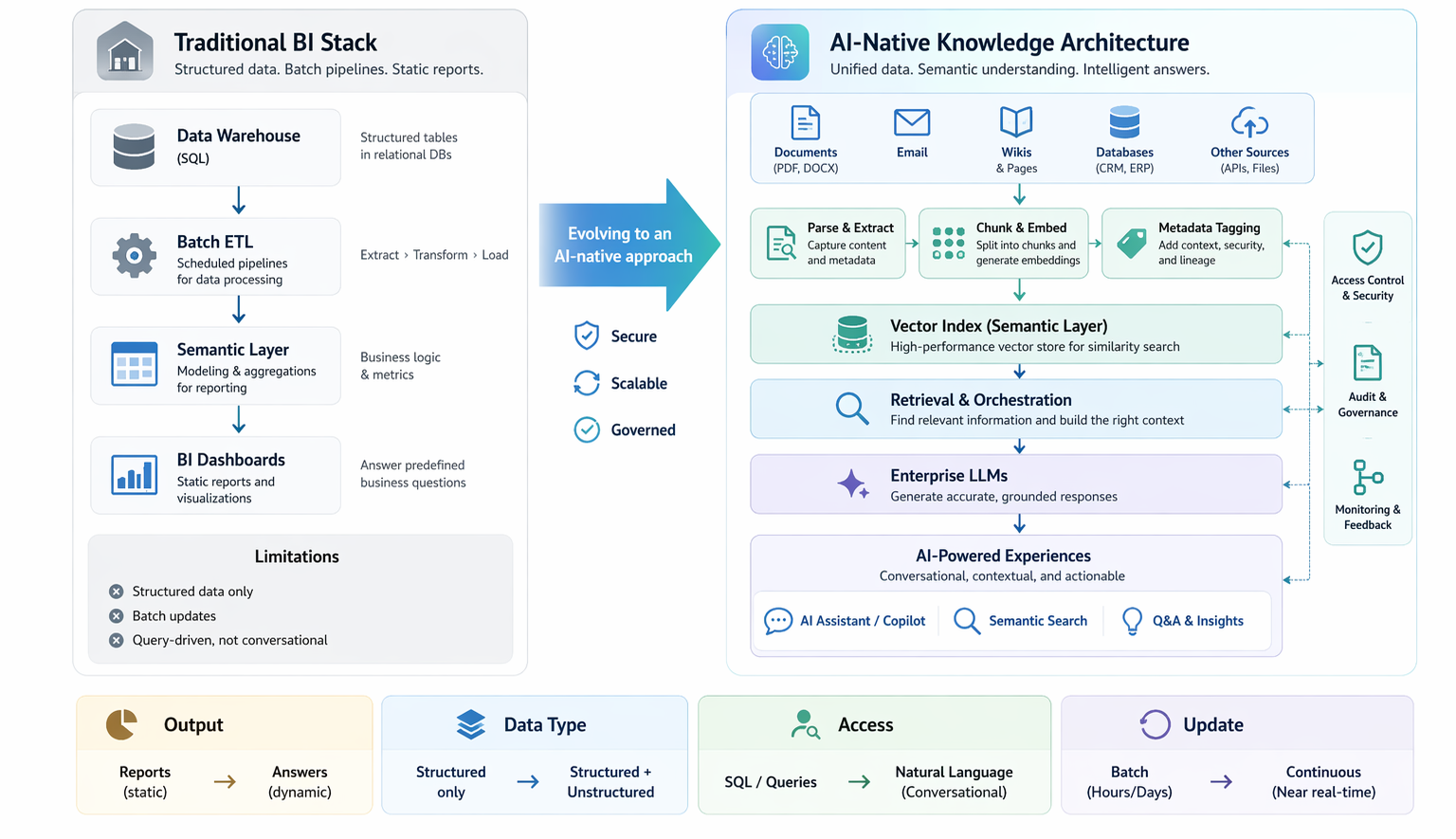
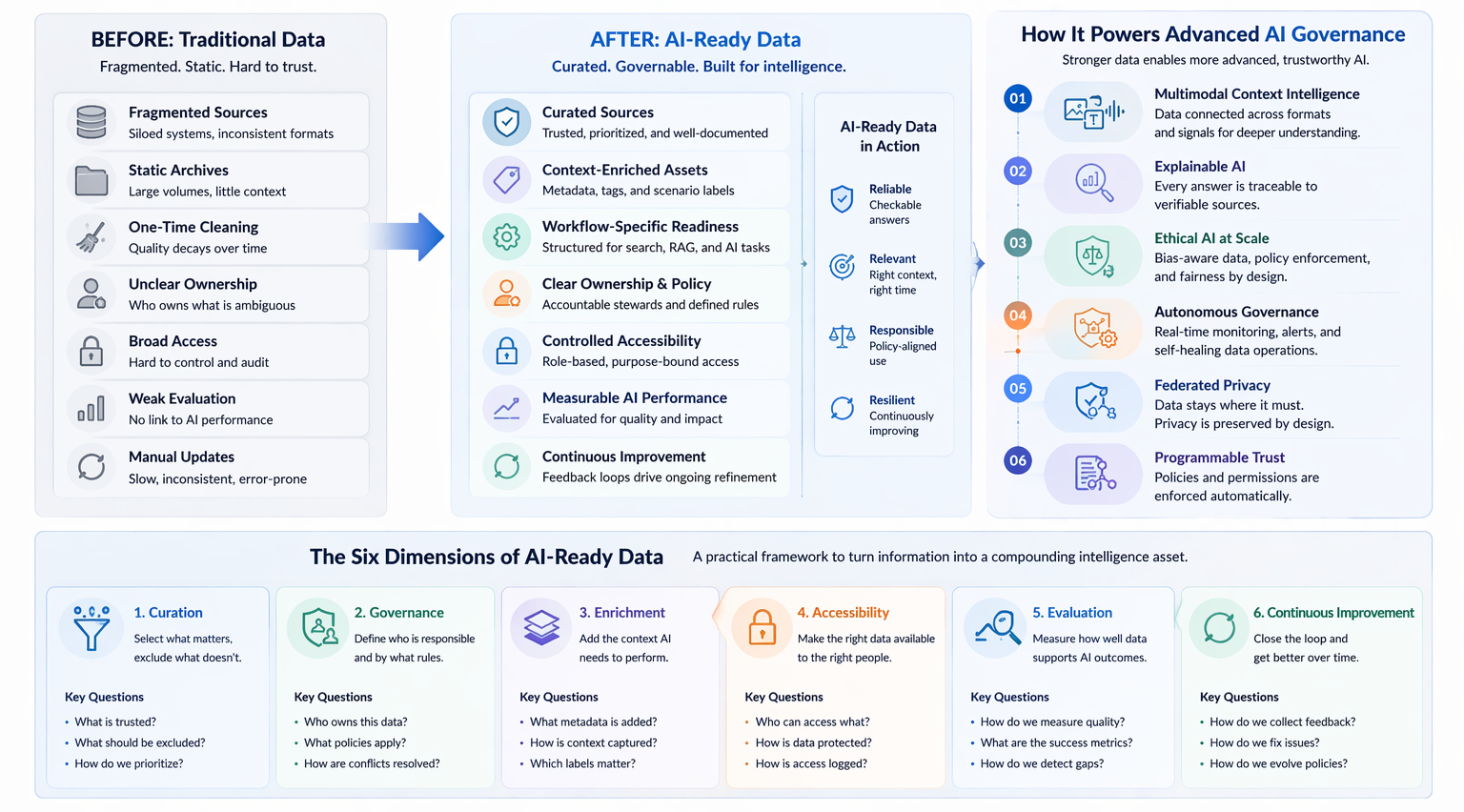
One of the quiet inefficiencies inside many enterprises is that valuable data exists in one part of the organization without the rest of the organization knowing it is available, understanding how to access it, or knowing whether it is AI-ready. This creates a paradox: enterprises that are data-rich at the aggregate level are data-poor at the team level, because the mechanisms for discovering and accessing useful internal data are weak or nonexistent.
This problem becomes more costly as AI investment increases. Data science teams spend significant time searching for relevant internal datasets, negotiating access with data owners, evaluating fitness for AI use cases, and managing the logistics of data transfer. These activities are productive in the sense that they sometimes succeed, but they represent enormous organizational friction that compounds across every AI project in the portfolio.
Internal data markets are a structural response to this problem. The concept is straightforward: create a discoverable, searchable catalog of internal data assets with clear metadata about content, quality, access requirements, and AI-readiness, alongside mechanisms for teams to request and receive access efficiently. The goal is to make internal data as easy to discover and acquire as external data purchased from vendors, but without the cost and with the advantage of domain relevance.
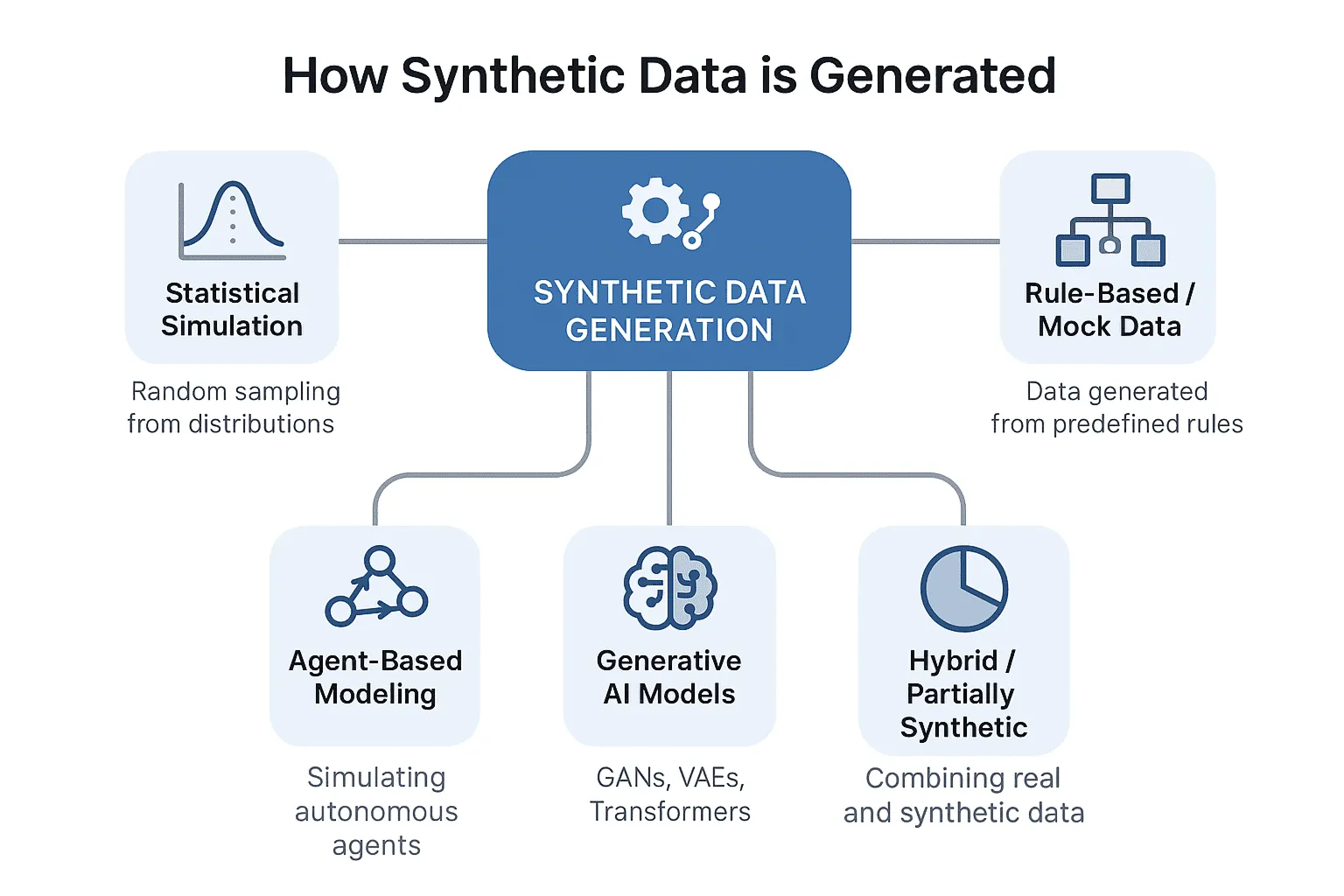
Building an internal data market requires investment in data cataloging infrastructure, metadata standards, ownership assignment, and access workflow tooling. It also requires a cultural shift: data owners must be willing to document and share their assets rather than treating them as departmental property. This cultural dimension is often harder than the technical one, but organizations that have made both investments report substantial reductions in project-level data acquisition friction.
The AI-readiness dimension adds a specific layer of value. Not all data is equally useful for AI applications, and teams waste significant time discovering this after they have already invested in access negotiation and initial preparation. An internal data market that includes AI-readiness assessments — covering labeling status, coverage distribution, known gaps, and recommended use cases — allows teams to make faster, better-informed decisions about which data sources to pursue.
As enterprise AI portfolios grow, the cost of weak internal data markets scales proportionally. Every new AI project that must rediscover and re-negotiate access to data that already exists and was previously prepared for a similar project represents pure organizational waste. Enterprises that invest in internal data market infrastructure are building a capability that becomes more valuable with each additional project, creating a compounding return on what initially appears to be a pure overhead investment.