A familiar pattern has emerged across enterprise AI adoption. Organizations invest significantly in model selection, infrastructure procurement, and team hiring. They run successful pilots with curated datasets. Then, when it is time to move toward production, the project stalls. The failure point is almost never the model itself. It is the data pipeline that feeds it.
This pattern repeats because enterprises typically underestimate how much invisible complexity lives between raw data and usable AI inputs. The model requires clean, consistent, well-structured inputs. But enterprise data environments were not built with AI in mind. They were built for operations, compliance, reporting, and storage. The gap between those two purposes is where projects slow down or stop entirely.
What makes this gap particularly frustrating is that it is not always visible at the pilot stage. Pilots often succeed because data engineers manually prepare a small, clean dataset that makes the system look promising. But replicating that preparation at production scale, across multiple data sources, with live updates, and under governance constraints, is an entirely different engineering challenge. Organizations that do not invest in pipeline infrastructure early discover this difference only after significant time and money have been spent.
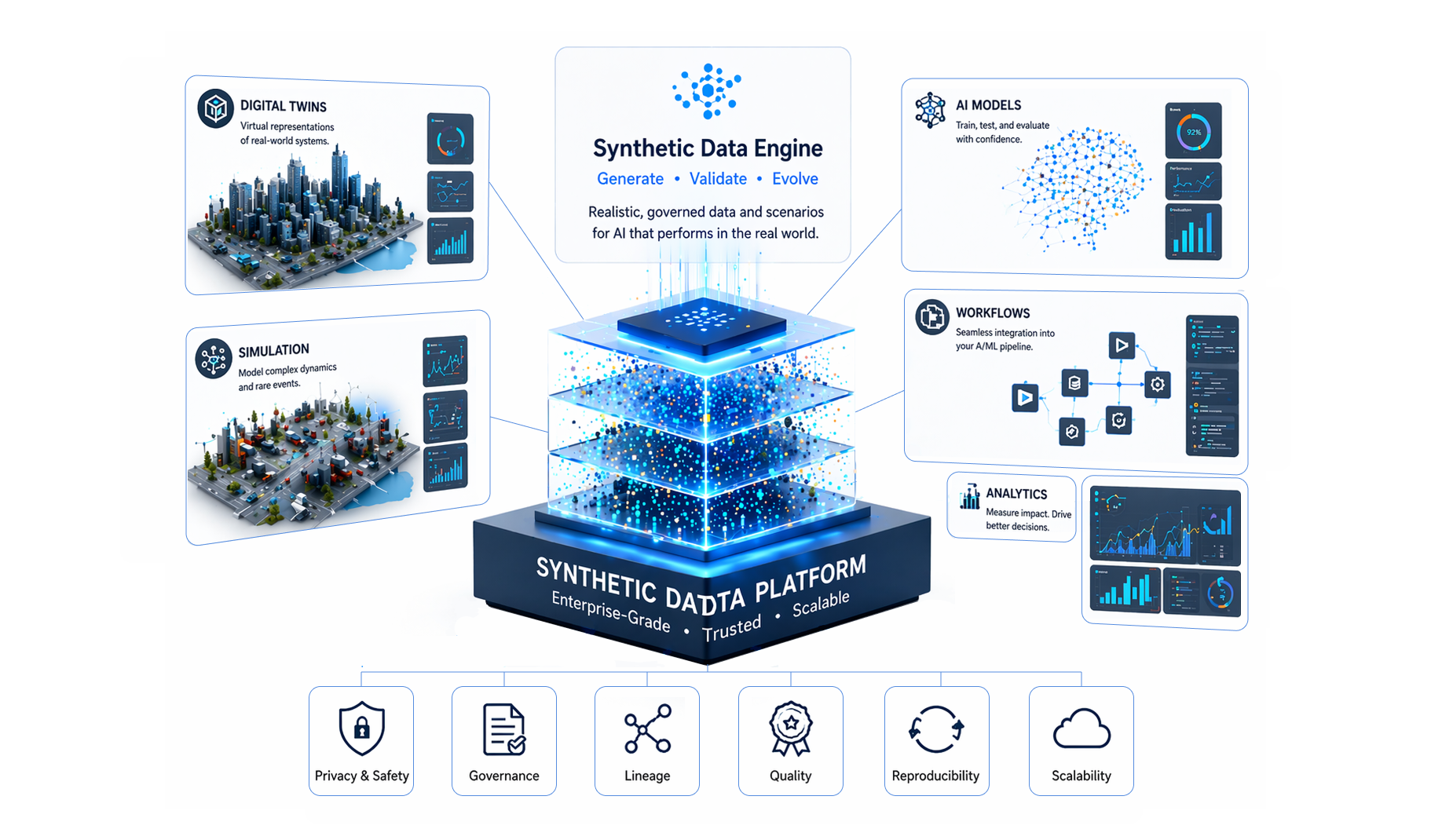
The solution is not simply to clean data better or hire more data engineers. It requires a structural rethinking of how enterprise data flows from source systems to AI consumption layers. This means investing in schema standardization, metadata governance, data versioning, and pipeline orchestration well before model development begins. It means treating the data pipeline as a first-class product, not as plumbing to be handled last.
Organizations that have successfully moved enterprise AI from pilot to production almost always share one characteristic: they invested in pipeline infrastructure before it became the bottleneck. They treated data readiness as a prerequisite, not an afterthought. That discipline is what separates enterprises that demonstrate AI from enterprises that deploy it.
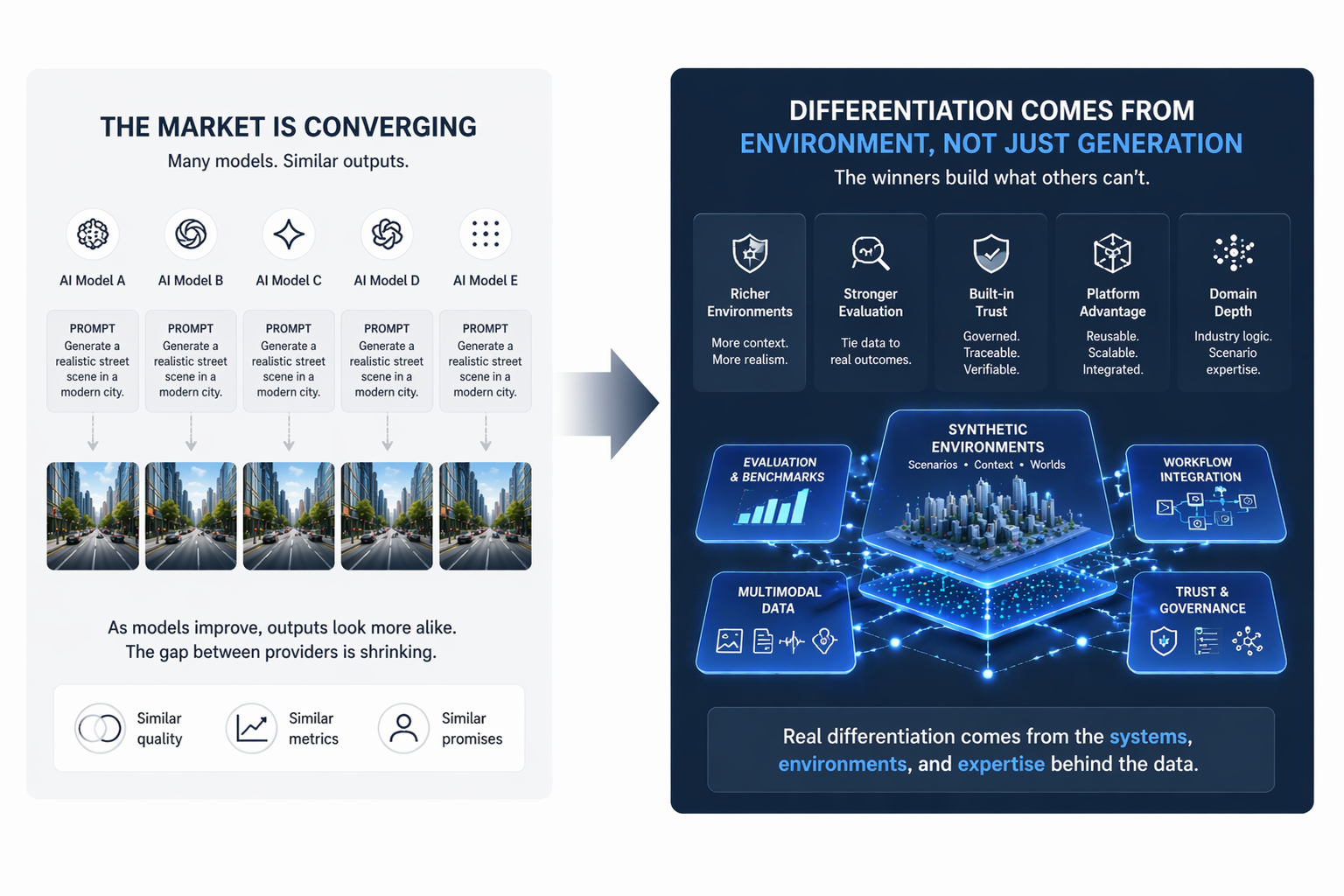
The implications for enterprise AI strategy are significant. Procurement and investment decisions that focus only on model capability or compute infrastructure miss the layer where most projects actually fail. A better model does not compensate for a broken pipeline. The organizations that are learning this lesson early are the ones building durable AI capabilities. Those that continue to treat data infrastructure as secondary are likely to keep encountering the same stall point, regardless of how many times they try.
