Over the past year, enterprise AI adoption has accelerated from isolated experimentation to a broader strategic agenda. Leadership teams are no longer asking whether AI matters. They are asking how quickly it can be integrated into real workflows, how much efficiency it can unlock, and how effectively it can become part of everyday operations. Yet beneath that momentum lies a more difficult and more practical concern. The real obstacle for many organizations is not lack of interest, lack of compute, or even lack of models. It is the question of how to experiment with AI without exposing the most sensitive parts of the business.
This is where many promising AI initiatives begin to slow down. On paper, experimentation seems simple. A company selects a model, connects internal documents or business data, tests use cases, and measures the results. In reality, enterprise data is not neutral material that can be moved freely into any AI workflow. It contains customer information, financial records, internal communications, security logs, design assets, product specifications, healthcare data, supplier agreements, legal language, and confidential operating logic. Even basic internal documents may reveal more than organizations are comfortable sharing in an unconstrained environment. As soon as those assets are involved, AI experimentation stops being a pure innovation exercise and becomes a question of governance, accountability, and exposure control.
This is why safe experimentation has become a foundational requirement for enterprise AI. If organizations cannot create trusted environments for testing and iteration, AI adoption remains stuck at the level of disconnected pilots. Teams may be curious and ambitious, but without confidence in data handling, experimentation becomes politically fragile. Security teams become cautious. Compliance teams become defensive. Business units hesitate to contribute meaningful internal data. Employees avoid using prototypes for anything real. Leadership may approve AI in principle while simultaneously blocking the conditions needed for effective development. In many organizations, this is the hidden reason why AI enthusiasm does not translate into sustained operational progress.
Safe experimentation begins with a shift in mindset. Instead of asking how quickly real internal data can be fed into a model, enterprises need to ask what kind of experimentation environment allows learning without unnecessary exposure. This distinction is critical. The goal of early AI work is usually not to expose the full depth of sensitive organizational knowledge all at once. It is to validate use cases, test workflows, understand model behavior, assess user interaction patterns, and determine whether the system can create meaningful business value. Much of this can be done without giving broad, uncontrolled access to raw sensitive information.
A strong starting principle is to separate innovation from direct data exposure. This means building stages within the AI development process. Initial prototyping can be performed with non-sensitive or transformed data. Intermediate testing can happen inside controlled environments with restricted access. More advanced evaluation can use carefully governed internal datasets with traceability and policy oversight. Production deployment can then be treated as a separate step requiring stronger controls, logging, and review. This staged approach allows organizations to progress without forcing an all-or-nothing decision between total restriction and reckless openness.
One of the most effective tools in this process is privacy-preserving data transformation. Before enterprise data enters AI workflows, it can often be masked, anonymized, reduced, segmented, or restructured to minimize direct exposure. Names, account identifiers, addresses, proprietary strings, and highly sensitive attributes can be removed or abstracted depending on the use case. In many scenarios, the task the model must learn does not require full raw visibility into every detail. It requires the structure of the problem, not the exposure of the source. When organizations realize this, experimentation becomes much more practical.
Synthetic data also plays an increasingly important role in safe experimentation. In early AI development, teams often need representative examples rather than literal historical records. They need to test prompting strategies, workflow orchestration, edge-case handling, structured extraction, search quality, classification logic, or model evaluation design. Synthetic data can support these tasks by preserving task shape and operational relevance without exposing actual confidential records. This is especially useful in domains where raw internal data is either highly sensitive or too risky to circulate broadly during the experimental phase. Rather than delaying experimentation until every governance question is fully resolved, synthetic data creates a safer space for teams to move forward responsibly.
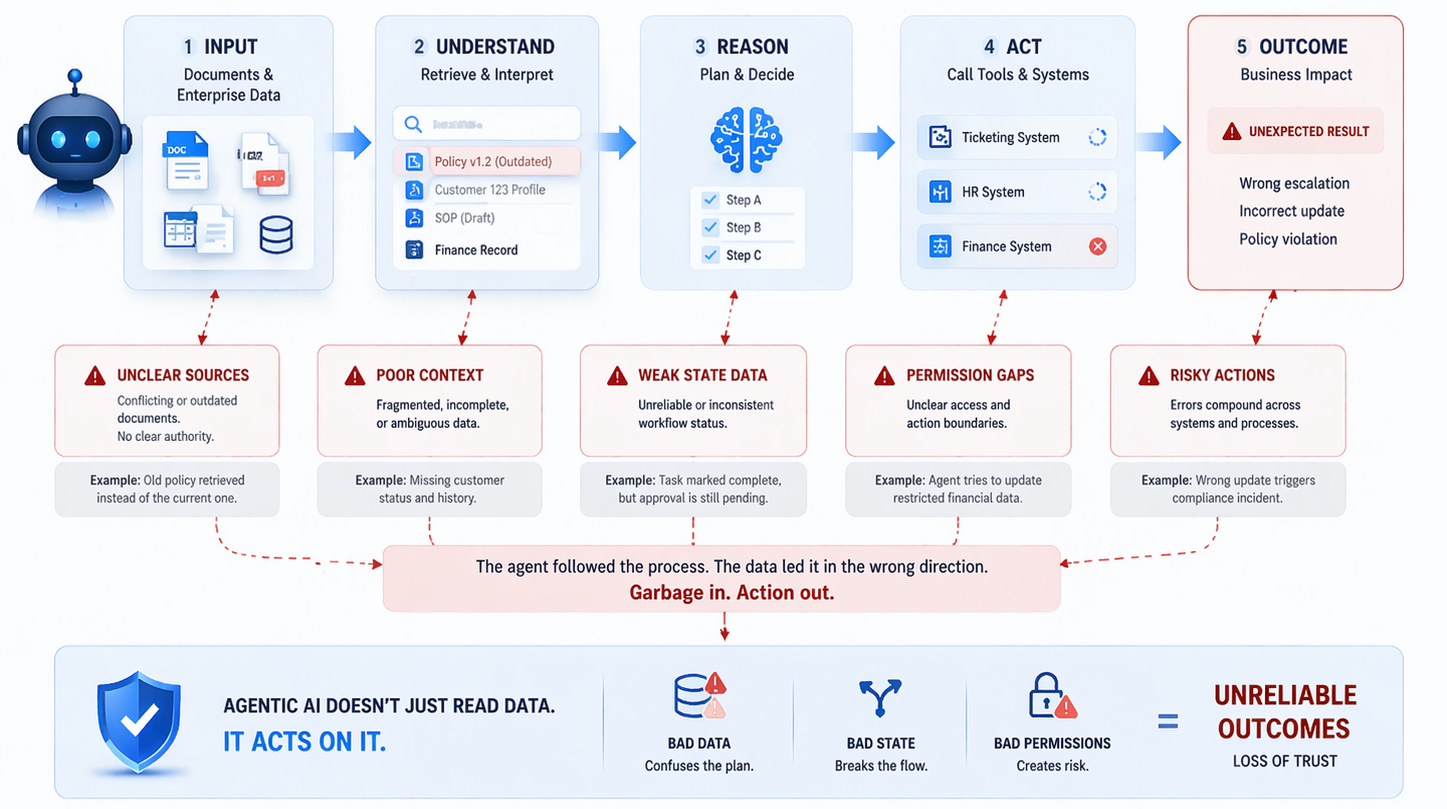
Another essential element is environment design. Enterprises need AI sandboxes that are intentionally built for controlled learning. These environments should not function as ad hoc spaces where teams casually upload internal material and test external tools without oversight. They should be bounded systems with permission structures, usage policies, isolated datasets, monitoring layers, and clearly defined objectives. This matters because experimentation itself generates new forms of risk. Prompts may reveal internal assumptions. Outputs may reconstruct sensitive information. Logs may contain traces of valuable content. Model behavior may look safe under casual testing while hiding meaningful vulnerabilities. A structured environment reduces these risks by making experimentation visible, reviewable, and repeatable.
This architectural containment also has a strategic advantage. Once safe environments exist, organizations can experiment more often and with greater confidence. Teams do not need to renegotiate trust from scratch every time a new AI idea appears. Security and compliance functions become enablers rather than blockers because the boundaries are already in place. Innovation accelerates not through relaxed standards, but through disciplined infrastructure. In this sense, safe experimentation is not the opposite of agility. It is what makes agility sustainable.
There is also a deeply human side to this issue. Enterprise AI does not succeed simply because a model is available. It succeeds when people inside the organization believe the system is safe enough to use, useful enough to matter, and controlled enough to trust. Employees will not meaningfully engage with AI tools if they suspect internal information might leak, be misused, or later be used against them. Business units will not contribute operational knowledge if experimentation feels opaque. Leaders will not scale pilots if they cannot confidently explain how data risk is being managed. Trust is therefore not a soft concept around AI adoption. It is part of the operational architecture.
This becomes even more important in sectors such as healthcare, finance, insurance, manufacturing, mobility, public infrastructure, and enterprise software, where sensitive information is inseparable from the workflows AI is expected to improve. In these sectors, experimentation cannot be treated as a purely technical matter. It must be designed with legal, operational, and organizational awareness. The most successful enterprise AI programs are not the ones that ignore these realities. They are the ones that absorb them into the design of the experimentation process itself.
It is also worth noting that safe experimentation is not only about preventing disaster. It is about generating better AI outcomes. When teams are forced to work in improvised, uncertain, or politically tense environments, experimentation quality suffers. People test less boldly. They avoid meaningful scenarios. They simplify tasks too much. They avoid internal data altogether or use it informally. This results in weak pilots that are neither safe nor useful. A governed experimentation process, by contrast, gives teams the confidence to ask better questions, run more realistic tests, and learn faster from results.
Ultimately, enterprises that treat AI experimentation as a controlled discipline will be better positioned than those that approach it as an unstructured race. The future of enterprise AI will not be shaped only by which organizations adopt models first. It will be shaped by which organizations build trusted systems for testing, validating, and scaling those models responsibly. That requires privacy-aware workflows, synthetic alternatives where appropriate, architectural isolation, access control, and transparent governance from the beginning.
That is how enterprises can experiment with AI safely without exposing sensitive data: not by slowing innovation, but by creating environments where privacy, security, and experimentation strengthen one another rather than compete. When that foundation is in place, AI stops being a risky curiosity and starts becoming an operational capability the organization can genuinely build upon.