For years, data quality was the dominant language of enterprise information management. Leaders asked whether data was complete, consistent, accurate, timely, and valid. But as enterprise AI becomes more deeply embedded in operations, a new distinction is becoming central. High-quality data is not always trusted data. And in 2026, that gap is becoming impossible to ignore.
This happens because enterprise AI is changing what data is expected to do. In earlier systems, clean data could support reporting, dashboards, search, and analytics even if some deeper contextual uncertainty remained hidden.
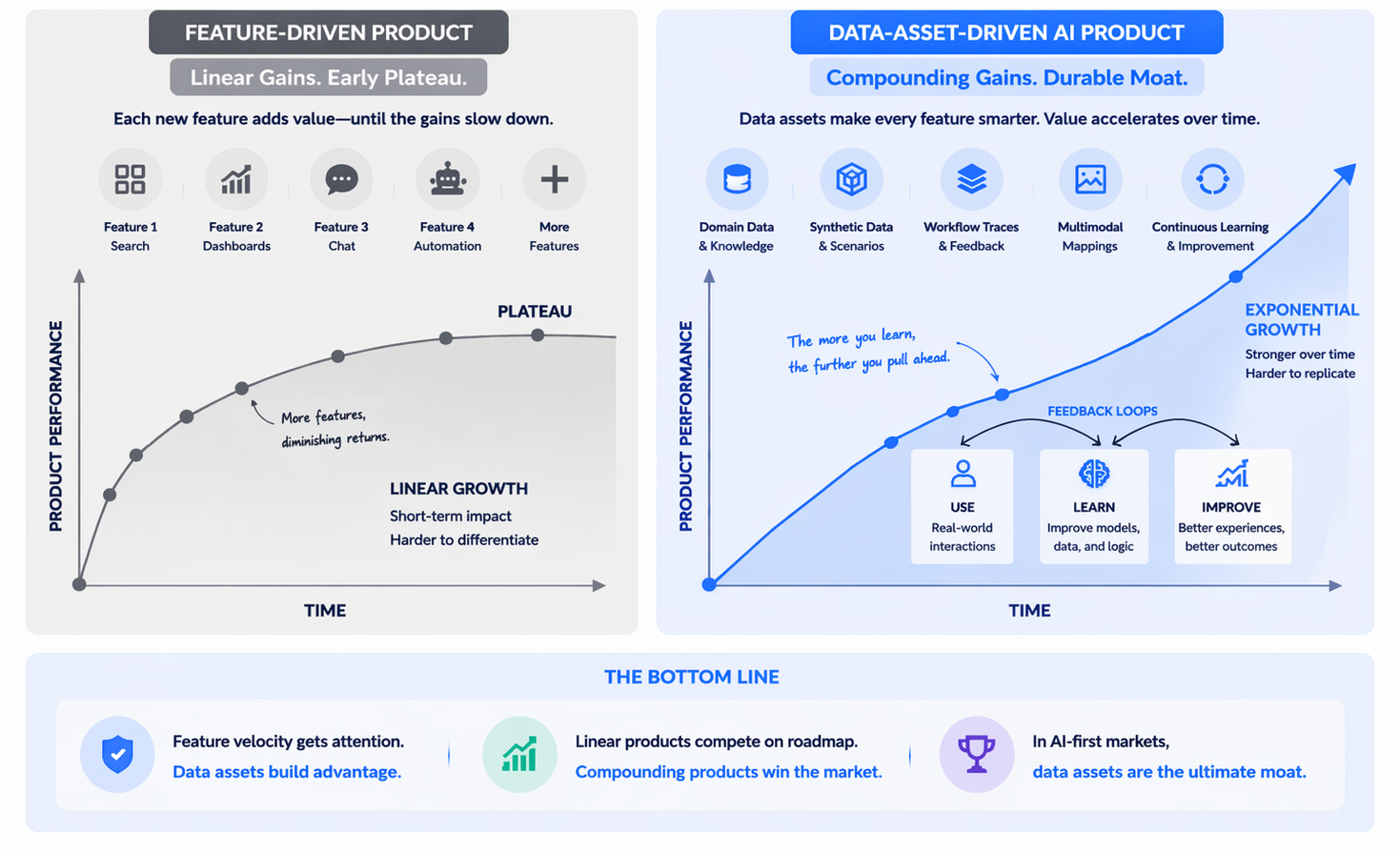
Data trust includes elements that conventional quality frameworks often underemphasize. It includes whether the source is authoritative for the use case, whether the information remains current in context, and whether the enterprise can explain how it was transformed.
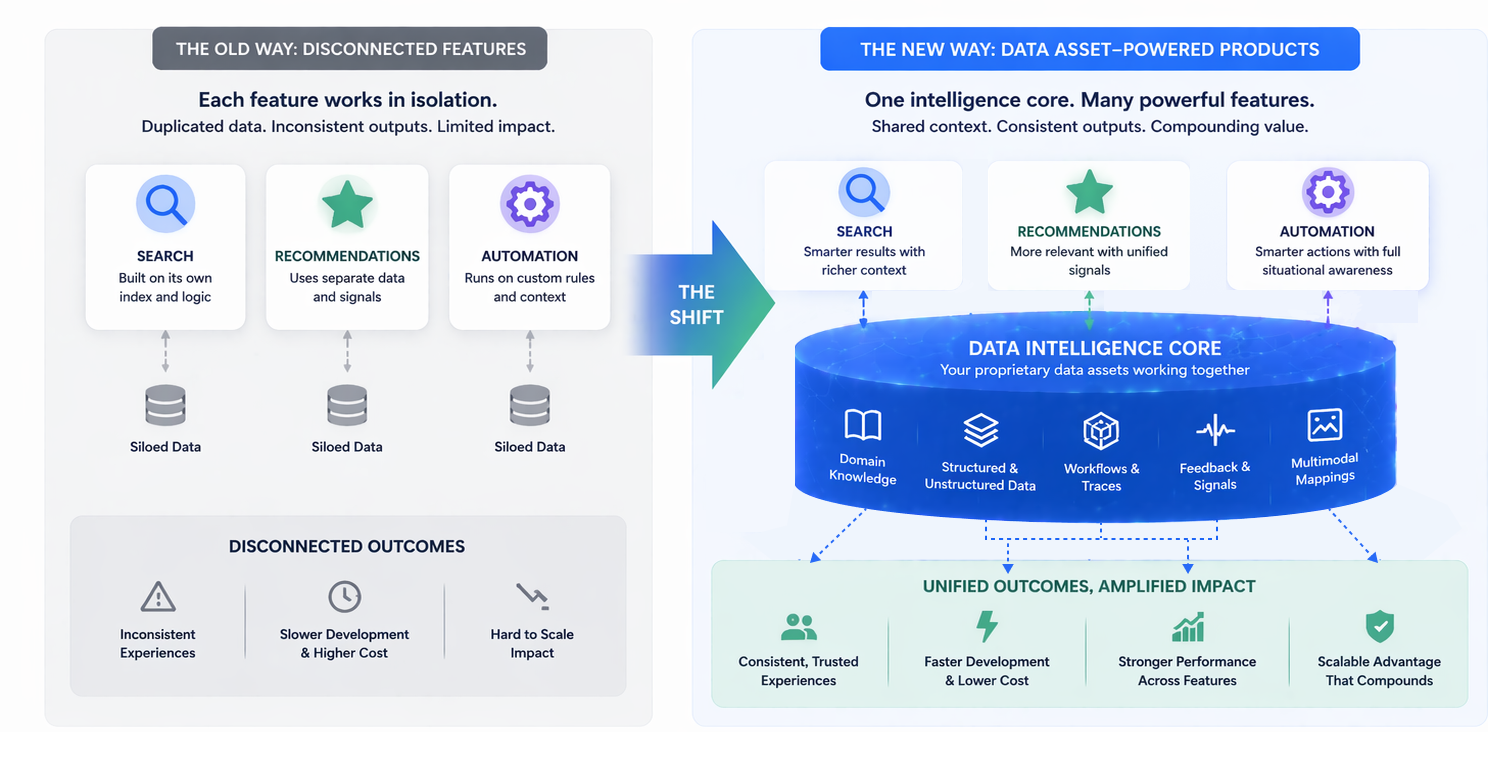
This is why the same data can be high-quality and still low-trust. A document set may be neatly organized, fully versioned, and technically accurate, yet still unsuitable for AI use if it mixes obsolete policies with current ones.
