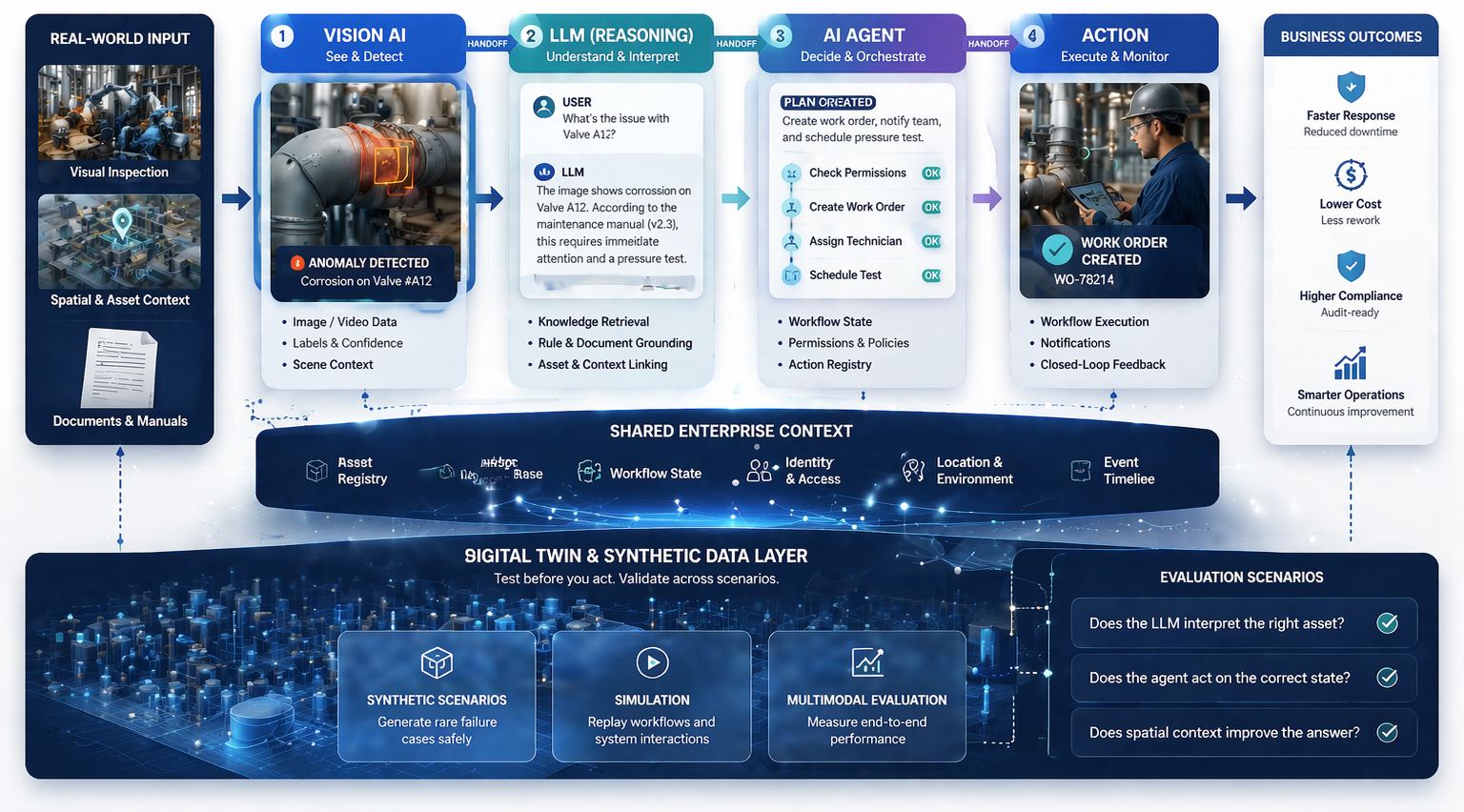
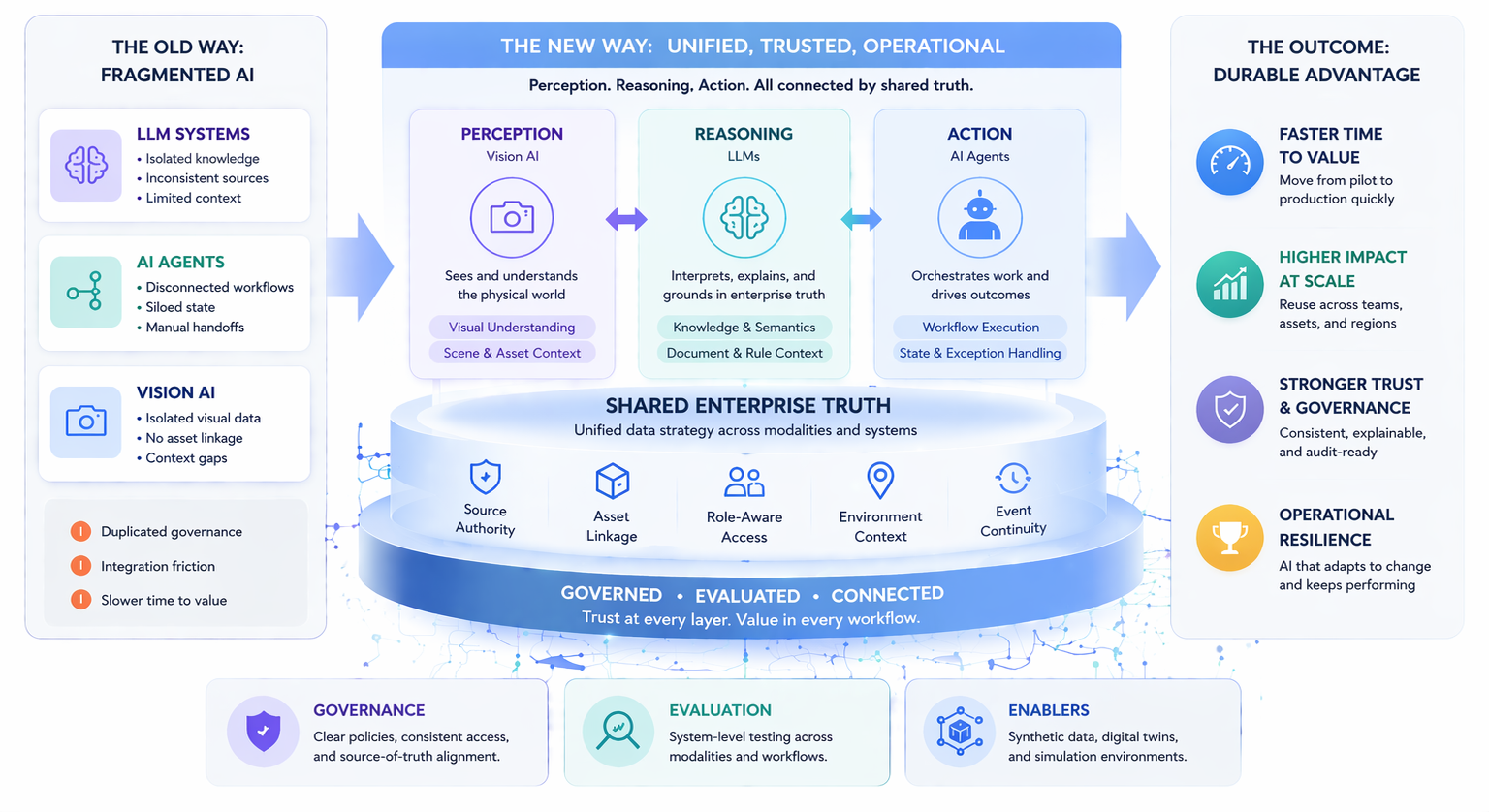
The first stage of LLM adoption inside an enterprise is often dominated by model questions. Which model should we use? How should we prompt it? What retrieval strategy makes sense? These are legitimate questions, and answering them well produces real results. But as organizations move from early adoption into more mature deployment, a different problem consistently surfaces: data consistency.
Data consistency failures in LLM deployments show up in a specific way. The model produces outputs that are technically coherent but factually inconsistent across different queries. It tells one user something different from what it tells another on the same topic. It retrieves information from conflicting sources without recognizing the conflict. It presents outdated guidance alongside current guidance with equal confidence. These failures are not model failures. They are reflections of inconsistency in the underlying data environment.
This becomes the second major bottleneck because it is harder to see than the first. Model capability failures are usually obvious — the system cannot do something it needs to do. Data consistency failures are subtle. The system appears to work, but the outputs cannot be trusted. In enterprise contexts, where decisions are made based on AI outputs, this subtlety is particularly dangerous. An LLM that produces inconsistent information may be actively harmful even while appearing functional.
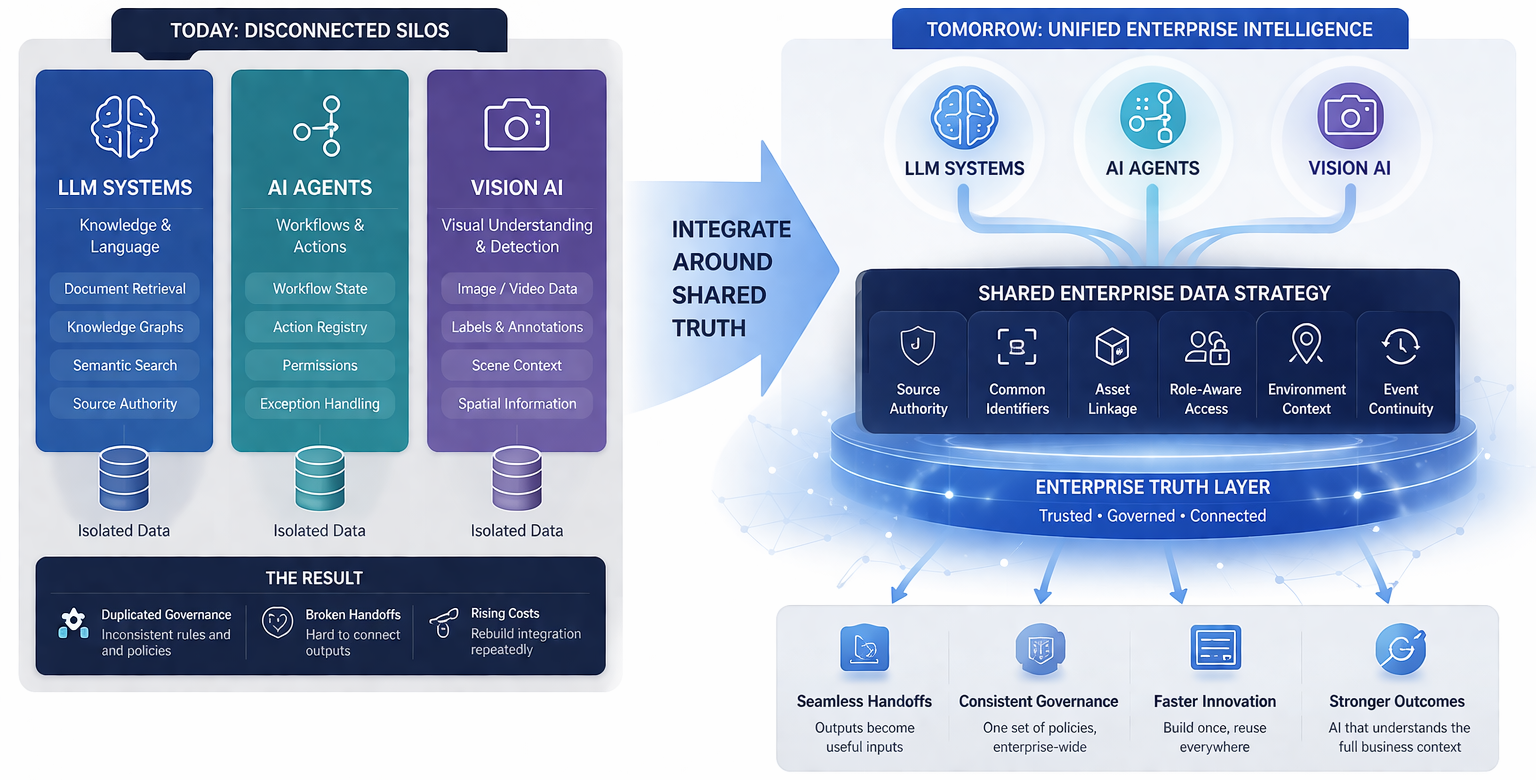
Addressing data consistency requires a different kind of investment than model improvement. It means auditing source materials for contradictions, establishing clear document authority hierarchies, retiring outdated content, implementing metadata standards that distinguish authoritative from informal sources, and building monitoring systems that detect when LLM outputs diverge from one another on the same query. These are data governance investments, not model investments.
Organizations that have invested in data consistency as part of their LLM deployment strategy report significantly better user trust metrics and lower rates of AI-related errors in downstream decisions. The model capability remains the same. The improvement comes entirely from the quality of the data environment supporting retrieval and grounding.
The practical implication is that LLM adoption roadmaps should explicitly plan for a data consistency phase. Organizations that treat LLM deployment as purely a model and infrastructure problem will almost inevitably encounter this second bottleneck at scale. Those that anticipate it and invest in data governance alongside model deployment will reach production-grade reliability faster and with lower total remediation cost.