The rise of AI agents has introduced a new level of ambition into enterprise AI planning. Where language models were largely used for retrieval and generation, agents are expected to plan, execute, decide, and act across complex multi-step workflows. That shift in capability demands carries with it a corresponding shift in data infrastructure requirements — one that most enterprises have not yet fully recognized.
Traditional AI infrastructure was designed to serve models that answered questions. An agent needs more than answers. It needs access to current, structured, and authoritative state information about the environment it is operating in. It needs to understand what has changed, what is allowed, what is risky, and what context is relevant to the current step of a task. This is a fundamentally different data contract than serving a language model query.
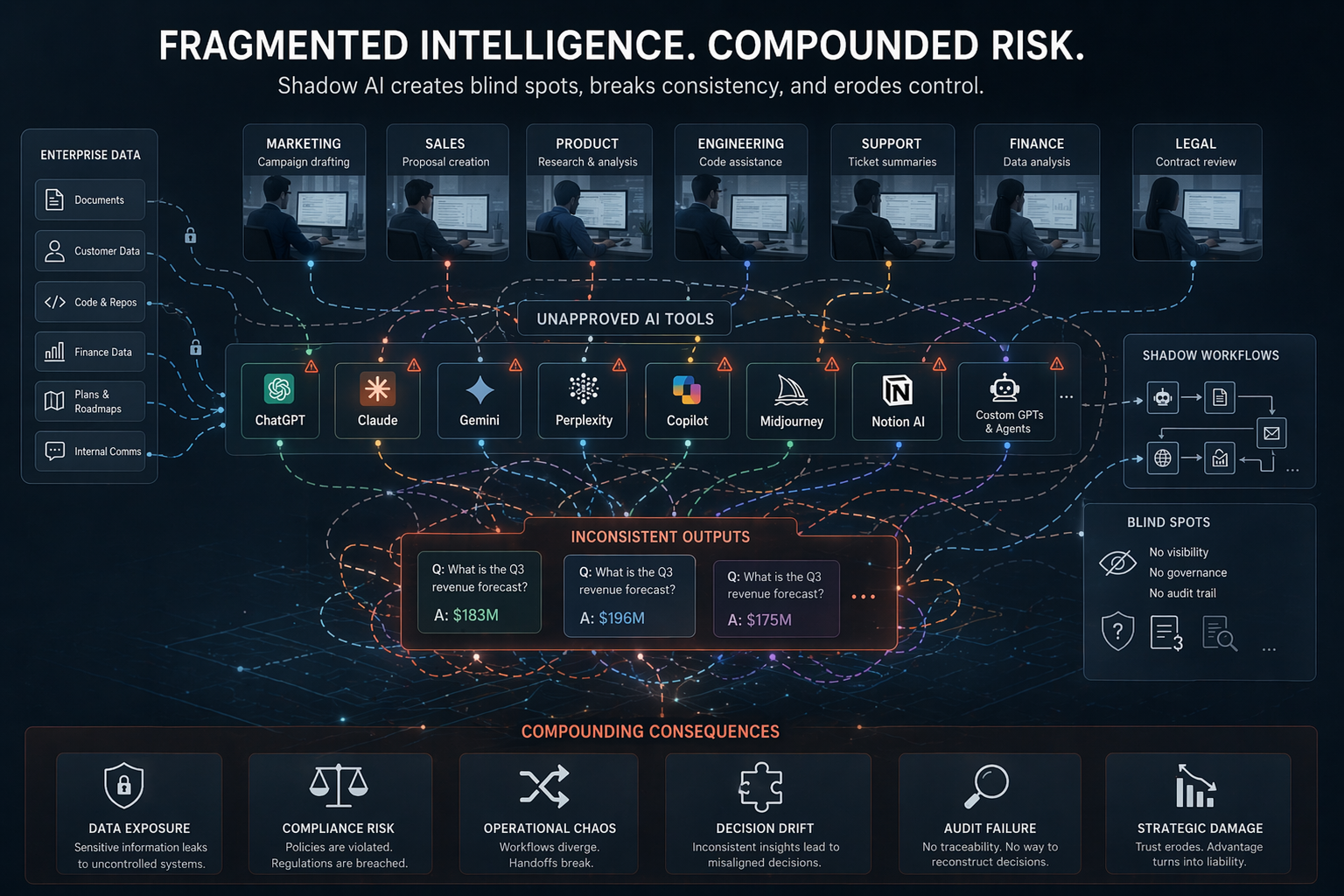
Most enterprise data environments were not designed to support this kind of real-time, contextually rich, multi-source data access. Data lakes contain historical records. Document stores contain unstructured text. Operational databases are often locked behind APIs not designed for agent consumption. Metadata is sparse or inconsistent. This means that agent systems, when deployed against real enterprise environments, frequently fail not because the agent logic is wrong, but because the data layer cannot support the decisions the agent needs to make.

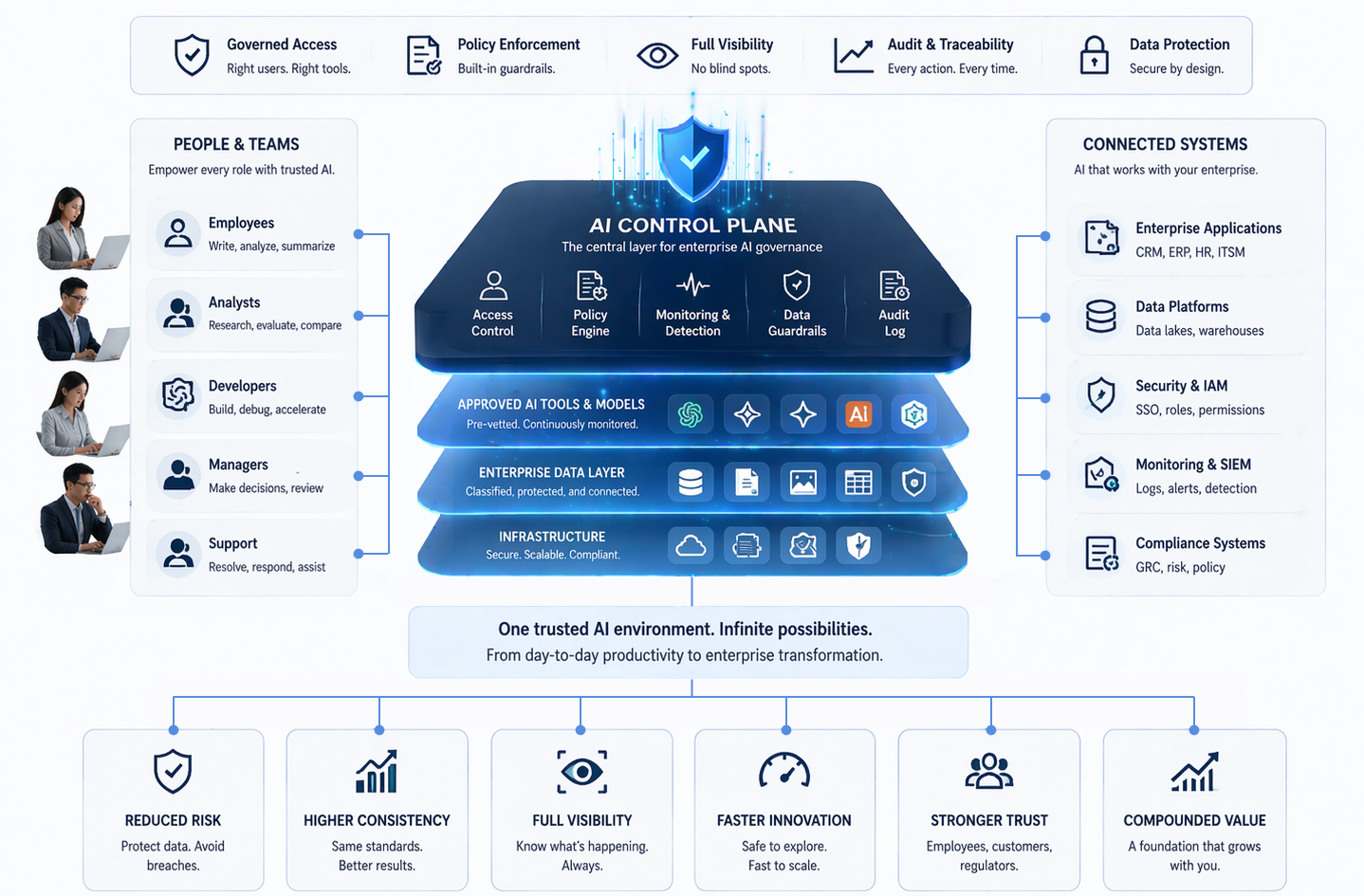
The redesign required is substantial. It involves creating data access layers that are agent-aware: capable of providing structured, grounded, real-time context with appropriate access controls and auditability. It means building knowledge graphs or structured memory systems that agents can query reliably. It means establishing clear data ownership and update frequencies so agents can reason about data freshness. These are not incremental improvements to existing infrastructure. They are architectural changes.
Enterprises that approach the agent era by simply deploying agent frameworks on top of existing data infrastructure will face the same pipeline stall problem at a higher level of complexity. Agents that cannot trust their data will make poor decisions, require constant human correction, or fail silently in ways that are harder to diagnose than model errors. The investment in data infrastructure redesign is therefore not optional for organizations that want reliable agent behavior.
The organizations that get this right will have a substantial advantage. Reliable agent systems that can navigate complex enterprise workflows autonomously represent a meaningful step change in operational efficiency. But reaching that state requires treating data infrastructure as a first-order problem, not a downstream consequence of agent deployment. The agent era will belong to enterprises that redesign their data layer before they deploy their agents.